





AI language models could help diagnose schizophrenia
SOURCE: HTTPS://WWW.SCIENCEDAILY.COM/
OCT 09, 2023
What is OpenAI’s DALL·E ? and why does it matter?
SOURCE: C-NEMRI.MEDIUM.COM
MAY 03, 2022
We are going to talk about an AI prowess that has been in the news a lot lately. In a nutshell, OpenAI’s DALL·E is able to generate accurate images to match a provided text prompt. Our AI artist was named after the artist Salvador Dalí and Pixar’s WALL·E.
Throughout this article, we will learn about the following:
So, what is DALL·E ? In July, OpenAI’s GPT-3 was able to generate Op Eds, poems, sonnets and computer code. DALL·E is a 12-billion parameter version of the GPT-3 Transformer model that interprets natural language inputs (such as “a green leather purse shaped like a pentagon” or “an isometric view of a sad capybara”) and generates corresponding images.
In one example from OpenAI’s blog, the model renders images from the prompt “a living room with two white armchairs and a painting of the colosseum. The painting is mounted above a modern fireplace”:

As you can see, OpenAI’s DALL·E can generate a large set of images from a prompt. The pictures are then ranked by a second OpenAI model, called CLIP, that tries to determine which picture matches the most common ones in a photo-editing task.
It uses the same neural network architecture that’s responsible for tons of recent advances in ML: the Transformer. Transformers are an easy-to-parallelize type of neural network that can be scaled up and trained on huge datasets. They’ve been particularly revolutionary in natural language processing, improving the quality of Google Search results and translation.
Most of these big language models are trained on enormous text datasets like Wikipedia or crawls of the web. DALL·E was trained on sequences that were a combination of words and pixels — we don’t know what the dataset was, but it was probably massive. OpenAI has yet to publish a full paper.
It is legitimate to wonder whether the results are merely high-quality because they’ve been copied or memorized from the source material. To prove its chops, the researchers forced DALL·E to render some pretty unusual prompts, such as “a professional high-quality illustration of a giraffe turtle chimera”.

Or “an illustration of a baby daikon radish in a tutu walking a dog”

It’s hard to imagine the model came across many giraffe-turtle hybrids in its training data set, making the results more impressive.
What’s more, these weird prompt hint at something even more fascinating about DALL·E: its ability to perform “zero-shot visual reasoning.”
OpenAI’s DALL·E was trained to generate images from captions. But with the right text prompt, it can explore a diverse set of capabilities, including creating anthropomorphized versions of animals and objects, combining unrelated concepts in plausible ways, rendering text, and applying transformations to existing images.
This is the first time a machine has been able to perform tasks that it wasn’t specifically trained to do. Here are examples of those capabilities:
Text prompt: “the exact same cat on the top as a sketch on the bottom”
Result:

Text prompt: “a store front that has the word ‘openai’ written on it”
Result:

Text prompt: “a small red block sitting on a large green block”
Result:

c
Text prompt: “a photo of the food of china”
Result

Text prompt: “a photo of a phone from the 20s, 30s, …”
Result

OpenAI researchers asked DALL·E to complete the bottom-right corner of each image using argmax sampling, and they considered its completion to be correct if it is a close visual match to the original.
Text prompt: “a sequence of geometric shapes”
example image prompt:

Result
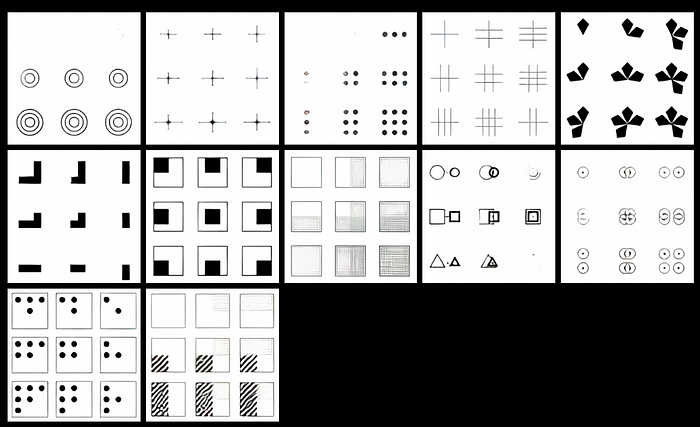
Of course, this is not to be confused with broad intelligence. It’s not difficult to fool these models into seeming stupid. We’ll know more once they’re open to the public and we can start messing with them. But that doesn’t stop me from being excited in the meanwhile. For instance, inverting the colors for the visual IQ test impacts DALL·E negatively while it should pose no additional difficulty for a human.
OpenAI’s DALL·E isn’t open to the public yet. Nonetheless, a team of Deep Learning practitioners have developed DALL·E mini, a small scale model generating images from text prompts using the very same technology that brought OpenAI’s DALL·E into existence, transformers. You can mess up with it here: https://huggingface.co/spaces/dalle-mini/dalle-mini
Here is the Github repo of the project if you want to inspect the source code: https://github.com/borisdayma/dalle-mini

Let’s connect on LinkedIn. I am a passionate Cloud, Data & AI Specialist, I hold Engineering and MS degrees from Georgia Institute of Technology ???????? and INP Toulouse ENSEEIHT ????????.
I am an AWS Community Builder, a Disability Rights Activist, and a Cloud Data Engineer at DataScientest, a French EdTech Start-up. I’ve been working for Data Consulting companies to help customers solve their Machine Learning and Big Data Analytics problems.
I mentor people with disabilities to land a career in tech: Book your spot with me here ???? https://calendly.com/nemri/techies-w-disabilities
I write about Data, Cloud and AI here ???? https://c-nemri.medium.com/
LATEST NEWS
WHAT'S TRENDING


Data Science
5 Imaginative Data Science Projects That Can Make Your Portfolio Stand Out
OCT 05, 2022

SOURCE: HTTPS://WWW.SCIENCEDAILY.COM/
OCT 09, 2023
SOURCE: HTTPS://WWW.THEROBOTREPORT.COM/
SEP 30, 2023
SOURCE: HTTPS://WWW.SCIENCEDAILY.COM/
AUG 08, 2023



SOURCE: HOUSTON.INNOVATIONMAP.COM
OCT 03, 2022

SOURCE: MEDCITYNEWS.COM
OCT 06, 2022