





White Castle to deploy voice-enabled digital signage in US
SOURCE: HTTPS://WWW.VERDICTFOODSERVICE.COM/
OCT 04, 2023
Top 5 Speech Recognition Data Collection Methods in 2023
SOURCE: HTTPS://RESEARCH.AIMULTIPLE.COM/
JUL 12, 2023

From automotive cars to healthcare diagnosis, speech/voice recognition applications are bringing advancements to many industries. Data is an integral part of developing and improving speech recognition systems since the overall level of system performance relies on data quality Apart from training, speech recognition systems regularly need to be improved with fresh data. Collecting or generating such data can be difficult, especially if the right method is not used.
In this article, we remedy this issue by exploring:
We have discussed data collection for AI/ML before. To summarize, it means gathering different types of data to prepare a dataset to develop or improve AI/ML models. For speech recognition, the type of data being collected is audio data, specifically; speech data generated by humans. This data is gathered to train/improve models that understand and generate natural language.
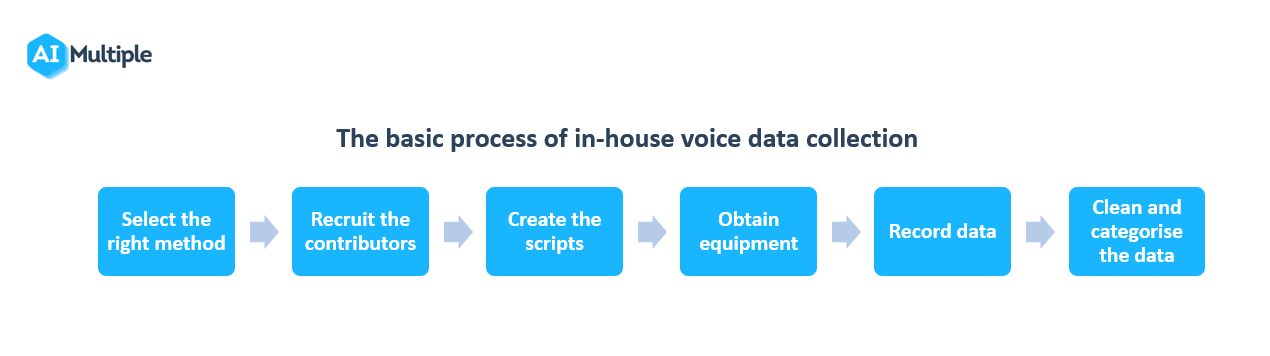
Considering the scope of your project and selecting the right voice data collection method is one of the most important initial steps of the process. For in-house voice data collection, the following basic steps can be considered:
Now that the data is collected and annotated, it is ready for AI/ML training.
This section will highlight the top methods of collecting voice/speech data:
Prepackaged voice datasets are suitable for developing and improving basic speech recognition models. They are ready-made datasets that are available online to purchase from different vendors.
Pre-packaged datasets are similar to public datasets. The only differences are that public datasets are usually free to access and offer a much lower level of quality and specificity. The purpose of creating public datasets is to support innovation in the speech recognition industry.
If the company does not wish to go through the hassle of managing data collection, which itself is a project, then it can outsource crowdsourcing. If data is required in multiple languages and dialects, the firm can also work with a third-party crowdsourcing service provider specializing in data collection/annotation.
Sponsored
Clickworker can offer scalable audio and voice datasets through a crowdsourcing model. Their crowd consists of over 4 million registered workers based all over the world who are proficient in more than 34 languages and dialects.
This is another way of collecting voice data that is commonly used (see video below) by brands. These brands typically offer speech recognition-powered solutions, such as smart home devices or virtual assistants.
Collecting voice data from your customers (users) can have many benefits:
Some of the negatives of collecting customer voice data are:
Collecting in-house voice data can also be a way of creating high-quality and unique datasets. This method is suitable for projects which do not require large datasets in multiple languages or dialects.
Selecting the right method for your speech recognition project depends on the following factors:
It is important to consider how big your project is. For instance, if a speech recognition system will be deployed in only one country, then pre-packaged or even public datasets can be used to train it. However, if it will be deployed in multiple countries and requires a dataset with multiple languages and dialects, then crowdsourcing would be a more suitable option.
If the data in question is not private, the government of the country in which the data is being collected allows companies to collect data from its customers, then customer speech data collection can be used.
On the other hand, if the project is confidential and the data can not be shared with the public, then in-house data collection can be more suitable.
As mentioned before, in-house data collection can be expensive and time-consuming; therefore, if the project has time and budget constraints, then working with prepackaged datasets or crowdsourcing data collection service providers can be more suitable.
By Shehmir Javaid, who is an industry analyst at AIMultiple. He has a background in logistics and supply chain management research and loves learning about innovative technology and sustainability. He completed his MSc in logistics and operations management from Cardiff University UK and Bachelor's in international business administration From Cardiff Metropolitan University U
LATEST NEWS
WHAT'S TRENDING


Data Science
5 Imaginative Data Science Projects That Can Make Your Portfolio Stand Out
OCT 05, 2022

SOURCE: HTTPS://WWW.VERDICTFOODSERVICE.COM/
OCT 04, 2023
SOURCE: HTTPS://RESEARCH.AIMULTIPLE.COM/
JUL 11, 2023


SOURCE: TECHCRUNCH.COM
OCT 27, 2022


SOURCE: THEHINDU.COM
OCT 16, 2022

SOURCE: BIOMETRICUPDATE.COM
SEP 30, 2022