





Hybrid AI-powered computer vision combines physics and big data
SOURCE: HTTPS://WWW.SCIENCEDAILY.COM/
AUG 14, 2023
Computer Science Researchers at Bytedance Developed Monolith: a Collisionless Optimised Embedding Table for Deep Learning-Based Real-Time Recommendations in a Memory-Efficient Way
SOURCE: MARKTECHPOST.COM
NOV 14, 2022

Over the past decade, a surge in the number of businesses powered by recommendation techniques has been observed. Delivering personalized content for each user as a real-time response is a common goal of these business applications in pursuit of a better customer experience. To that end, information from a user’s most recent interaction is frequently used as the primary input for training a model. It best depicts a user’s portrait and predicts their interest and future behaviors. Deep learning has dominated recommendation models because the massive amounts of user data are a natural fit for massively data-driven neural models.
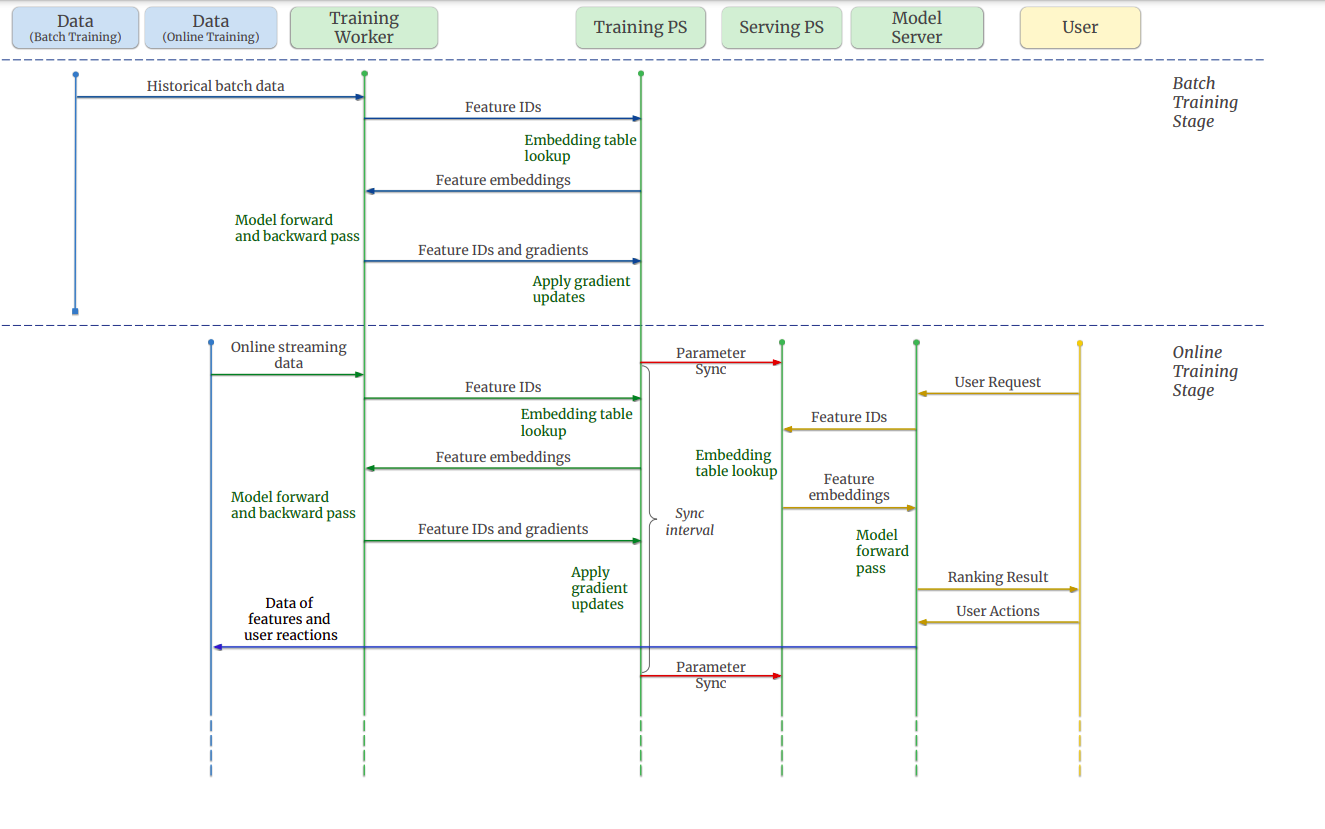
Online Training Architecture of Monolith
On the other hand, efforts to leverage the power of deep learning in industry-level recommendation systems need to be improved by issues arising from the unique characteristics of data derived from real-world user behavior. These data differ significantly from those used in traditional deep learning problems such as language modeling or computer vision in two ways: First, the features are mostly sparse, categorical, and changing dynamically, and secondly the underlying distribution of training data is non-stationary, also known as Concept Drift. These distinctions have presented novel challenges to researchers and engineers working on recommendation systems.
The recommendation data mainly contains sparse categorical features, some of which appear infrequently. The common practice of mapping them to a high-dimensional embedding space raises several issues. In contrast to language models, where the number of word pieces is limited, the number of users and ranking items is orders of magnitude greater. Worse, the size of the embedding table is expected to grow over time as more users and items are admitted, whereas frameworks like use fixed-size dense variables to represent the embedding table.
In practice, many systems use low-collision hashing to reduce memory footprint and allow IDs to grow. This is based on the overly idealistic assumption that IDs in the embedding table are distributed evenly in frequency and that collisions have no effect on model quality. Unfortunately, in a real-world recommendation system, a small group of users or items has significantly more occurrences. As the size of the embedding table grows organically, the likelihood of hash key collision increases, resulting in model quality degradation.

As a result, it is natural for production-scale recommendation systems to capture as many features as possible in their parameters and to be able to adjust the number of users and items they attempt to book-keep. Visual and linguistic patterns take centuries to develop, whereas the same user interested in one topic may change their zeal every minute. As a result, the underlying distribution of user data is non-stationary, known as Concept Drift. Intuitively, information from a more recent past can contribute more effectively to predicting a change in a user’s behavior.
To mitigate the impact of Concept Drift, serving models should be updated as close to real-time as possible based on new user feedback to reflect a user’s most recent interest. They designed Monolith, a large-scale recommendation system, to address these pain points in light of these distinctions and observations of issues that arise from their production. They conducted extensive experiments to validate and iterate their design in the production environment. By designing a collisionless hash table and a dynamic feature eviction mechanism, Monolith can 1. Provide full expressive power for sparse features
2. Loop serving feedback back to training in realtime with online training
Monolith consistently outperforms systems that use hash tricks with collisions with roughly similar memory usage and achieves state-of-the-art online serving AUC without overburdening their servers’ computation power.
Check out the paper. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.

Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
LATEST NEWS
WHAT'S TRENDING


Data Science
5 Imaginative Data Science Projects That Can Make Your Portfolio Stand Out
OCT 05, 2022

SOURCE: HTTPS://WWW.SCIENCEDAILY.COM/
AUG 14, 2023


SOURCE: INDIANEXPRESS.COM
OCT 24, 2022



