




{kind=link}
{kind=link}

CMU Researchers Introduce the Open Whisper-Style Speech Model: Advancing Open-Source Solutions for Efficient and Transparent Speech Recognition Training
SOURCE: HTTPS://WWW.MARKTECHPOST.COM/
OCT 03, 2023
Top Feature Stores for Machine Learning data scientists must know in 2022
SOURCE: MOEZ-62905.MEDIUM.COM
OCT 22, 2022

A feature store is a system for managing data that gives data scientists and engineers a central place to find and use data for machine learning. A feature store enables data / (features) to be shared across different machine learning pipelines, which can speed up the development of new models and improve model performance. Feature stores have recently emerged as an important component of the enterprise machine learning stack and is a key component in enabling:
The two main types of data in machine learning are:
These two types of data are managed by two types of feature stores:

In this blog, we will review some of the most popular feature stores in 2022.
The Feast feature store is an open source tool that provides a unified view of data for feature engineering, training, and serving machine learning models. It is designed to be scalable and extensible, and to support a wide variety of data sources and feature types.
Features

Feast is a Python library, so you can simply install it using pip. For more details, please see the quickstart guide
Airbnb’s data management system, Zipline, was created with ML use cases in mind. Previously, machine learning specialists at Airbnb spent about 60% of their time gathering and creating transformations for ML jobs. Zipline cuts the time it takes to do this task from months to days by making the procedure declarative. In a straightforward configuration language, it enables data scientists to quickly create machine learning features. The system then provides users with access to point-in-time correct features for offline model training and online inference.

To learn more about Zipline, watch this amazing talk by Varant Zanoyan.
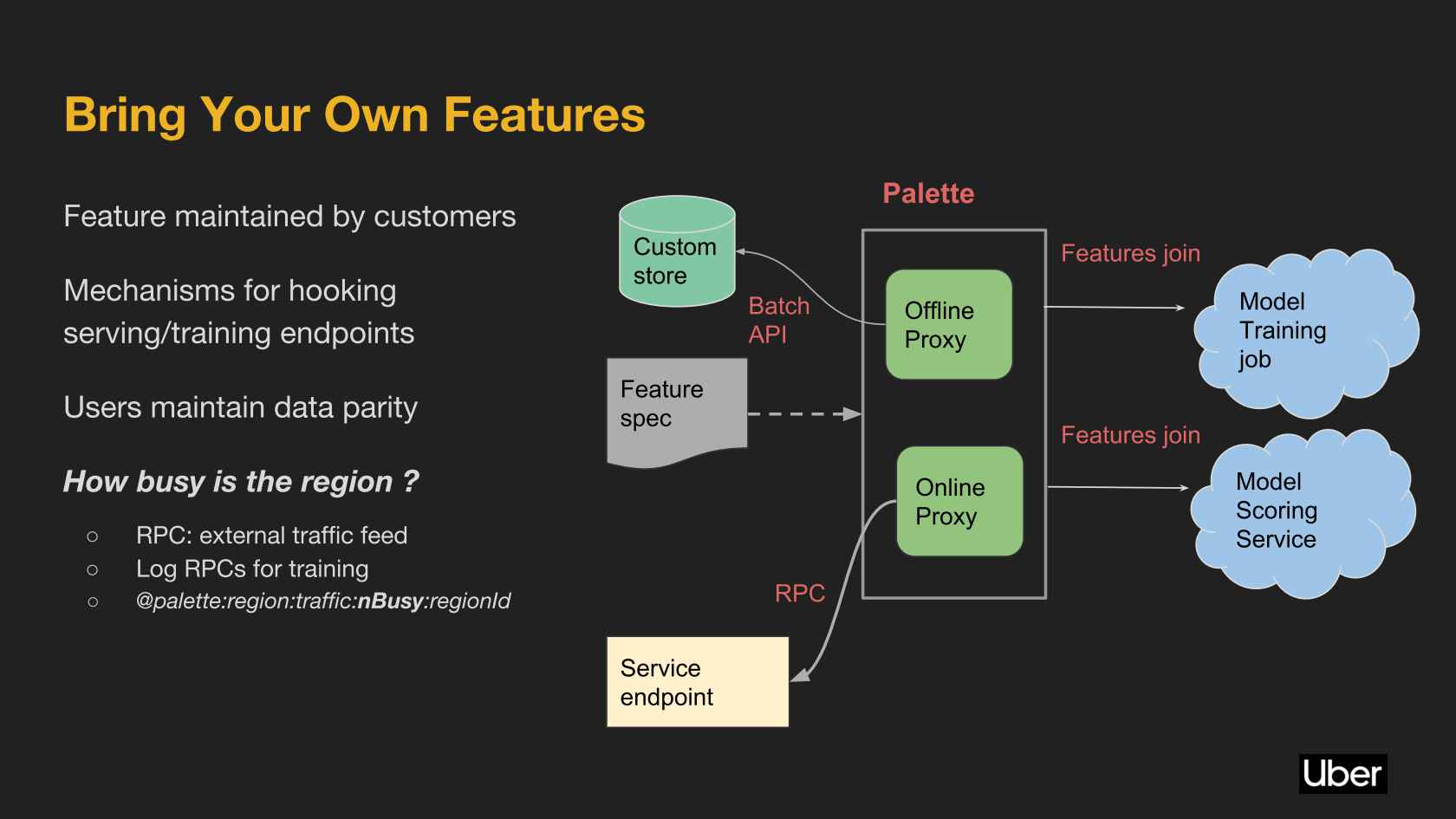
Michelangelo is a platform for machine learning created by Uber, focused on sharing machine learning feature pipelines with various teams within Uber.
Michelangelo Palette is a platform for machine learning that Uber uses internally to make it easy to add features to machine learning models that are already in use. Managing features for machine learning models is one of the biggest bottlenecks in productizing machine learning models.

To learn more about Uber’s Michelangelo platform and how they have built it, watch this presentation by Amit Nene and Eric Chen. This talk discusses the infrastructure built by Uber for the Michelangelo ML Platform that enables a general approach to feature engineering across diverse data systems.
Hopsworks is widely used as a stand-alone feature store. A feature store provides offline and online stores for large volumes of historical feature values and real-time access for current feature values. A feature store also provides an API for creating, reading, updating, and deleting feature values, and retrieving training data and feature vectors.
You can utilize your own data warehouse or lake as an offline store in addition to Hopsworks’ built-in offline store, which is based on Apache Hudi. Hopsworks comes with its own offline store. The offline store is where historical feature values are kept, and it is also where training data and features for offline batch scoring are retrieved.
Hopsworks online feature store is built on RonDB, the only database optimized for feature store use cases. The online store contains the latest feature values and is used to provide feature vectors to deployed models at runtime.

To start for free, check out this official guide.
In the context of machine learning and MLOps, feature stores are becoming a more popular part of data architecture. A feature store’s purpose is to simultaneously transform data from diverse data sources into features that the model training pipeline and the model serving pipeline may use. Feature Stores combine multiple data sources and preprocess those into features.
I write about data science, machine learning, and PyCaret. If you would like to be notified automatically, you can follow me on Medium, LinkedIn, and Twitter.
LATEST NEWS
Augmented Reality
Hi-tech smart glasses connecting rural and remote aged care residents to clinicians
NOV 20, 2023
WHAT'S TRENDING


Data Science
5 Imaginative Data Science Projects That Can Make Your Portfolio Stand Out
OCT 05, 2022

SOURCE: HTTPS://WWW.MARKTECHPOST.COM/
OCT 03, 2023
SOURCE: HTTPS://NEWS.MIT.EDU/
AUG 17, 2023
SOURCE: HTTPS://WWW.SCIENCEDAILY.COM/
AUG 21, 2023
SOURCE: HTTPS://WWW.SCIENCEDAILY.COM/
AUG 17, 2023
SOURCE: HTTPS://WWW.SCIENCEDAILY.COM/
AUG 07, 2023
SOURCE: HTTPS://WWW.INDIATODAY.IN/TECHNOLOGY/NEWS/STORY/69-MILLION-GLOBAL-JOBS-TO-BE-CREATED-IN-NEXT-FIVE-YEARS-AI-AND-MACHINE-LEARNING-ROLES-TO-GROW-IN-INDIA-2367326-2023-05-02
JUN 28, 2023