





CMU Researchers Introduce the Open Whisper-Style Speech Model: Advancing Open-Source Solutions for Efficient and Transparent Speech Recognition Training
SOURCE: HTTPS://WWW.MARKTECHPOST.COM/
OCT 03, 2023
Stanford researchers use deep learning to predict biological structures, like RNAs, more accurately than ever before
SOURCE: MARKTECHPOST.COM
SEP 05, 2021

Determination of 3D structures of biological molecules, like RNA’s, is difficult and often requires millions of dollars for such extensive efforts. Stanford University researchers have devised a new deep learning algorithm called ARES (Atomic Rotationally Equivalent Scorer) for overcoming this challenge by computationally forecasting accurate structures.
Even with insufficient data, the method accurately predicts the 3D forms of drug targets and other critical biological molecules. Therefore it can be used to determine the structures of molecules that are difficult to determine experimentally. The algorithm not only predicts but also explains how distinct molecules work, with applications ranging from basic biological research to informed drug design techniques.
The team describes the structure as the determining function in structural biology, which is the study of the forms of molecules. Proteins are molecular machines that carry out various tasks and frequently attach to other proteins to carry out their functions. Researchers having knowledge of protein pairs implicated in disease and their interaction in 3D can also target this interaction very specifically with therapy.
The team explains that traditional teaching techniques can often influence a calculation for specific elements, preventing it from identifying additional educational opportunities. Thus they used the machine to figure out these molecular characteristics independently rather than finding what makes an underlying forecast fairly accurate.
However, these hand-crafted features make the algorithm biased towards what the person who chooses these qualities believes is significant and miss out on information that would help it perform better.
The network was able to uncover essential concepts that are important in developing molecular structures without being explicitly trained. The team states that their algorithm has not only retrieved elements that were significant, but it has also recovered traits that were not known previously, which is interesting.
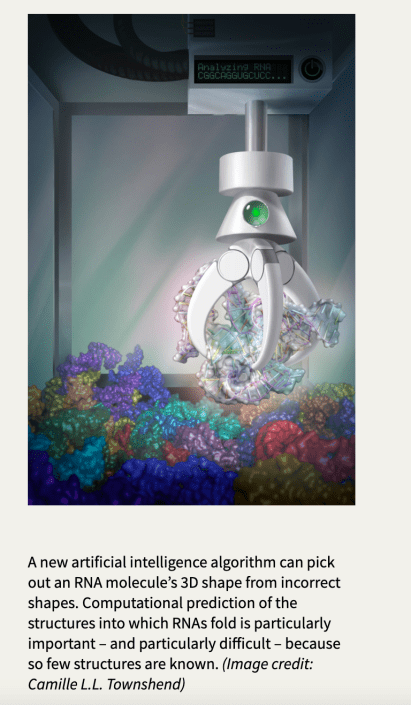
https://news.stanford.edu/2021/08/26/ai-algorithm-solves-structural-biology-challenges/
Next, the researchers tested their algorithm on another class of critical biological molecules, RNAs (a series of ‘RNA Puzzles’). The algorithm outperforms all the other puzzle participants without even being explicitly designed for RNA structures.
Most of the current advanced machine learning (ML) and deep learning algorithms require large amounts of data for training. Despite having broad scope, these algorithms cannot be employed in numerous cases due to the limited availability of data. The fact that this method works despite having very little training data suggests that similar techniques could solve unsolved problems in many fields where data is scarce.
The team believes that understanding this fundamental technology will pave the path for possible research and applications such as designing new molecules and medicines with this kind of information.
LATEST NEWS
Augmented Reality
Hi-tech smart glasses connecting rural and remote aged care residents to clinicians
NOV 20, 2023
WHAT'S TRENDING


Data Science
5 Imaginative Data Science Projects That Can Make Your Portfolio Stand Out
OCT 05, 2022

SOURCE: HTTPS://WWW.MARKTECHPOST.COM/
OCT 03, 2023
SOURCE: HTTPS://NEWS.MIT.EDU/
AUG 17, 2023
SOURCE: HTTPS://WWW.SCIENCEDAILY.COM/
AUG 21, 2023
SOURCE: HTTPS://WWW.SCIENCEDAILY.COM/
AUG 17, 2023
SOURCE: HTTPS://WWW.SCIENCEDAILY.COM/
AUG 07, 2023
SOURCE: HTTPS://WWW.INDIATODAY.IN/TECHNOLOGY/NEWS/STORY/69-MILLION-GLOBAL-JOBS-TO-BE-CREATED-IN-NEXT-FIVE-YEARS-AI-AND-MACHINE-LEARNING-ROLES-TO-GROW-IN-INDIA-2367326-2023-05-02
JUN 28, 2023