





Consumer Data Protection: Data Scientists And Data Security
SOURCE: WWW.DISCOVERDATASCIENCE.ORG/
AUG 14, 2023
News summary app with python
SOURCE: TOWARDSDATASCIENCE.COM
SEP 12, 2021

Photo by Roman Kraft on Unsplash
There’s a lot of news out there, and it’s hard to keep up. Since I’m not a speed reader, I was curious if I could find a pure Python solution to help me stay informed. I’ve used News API in the past, and I use Streamlit a lot for data science projects. After a quick search, I found sumy (Github), and it turned out to be a good solution for the text summarization element of the problem.
This article assumes some working knowledge of Python, Terminal, and APIs. Even if you’re unfamiliar with any of these topics, I think you’ll find most of it pretty manageable and fun.
pip install sumy
pip install streamlit
Sumy uses NLTK, which requires additional data to be downloaded, and you can find detailed instructions here.
This is how I did it on macOS:
Run the following code in a Python session:
This will launch the NLTK Downloader. For central installation, change the Download Directory text field to: /usr/local/share/nltk_data. If central installation causes permission errors, it’s fine to install the data elsewhere, but you will need to set the environment variable.
To add the environment variable using zsh, you can run the following command in Terminal:
echo "export NLTK_DATA= >> ~.zshenv"
Here are the import statements you will need to run the code:
from sumy.parsers.html import HtmlParser
from sumy.nlp.tokenizers import Tokenizer
from sumy.summarizers.lsa import LsaSummarizer as Summarizer
from sumy.nlp.stemmers import Stemmer
from sumy.utils import get_stop_words
import requests
news_imports.py hosted with ? by GitHub
The below function is a modified version of the example on the sumy Github page. The function simply ranks the sentences in the text, and returns a str with the most important sentences. The sentences_count argument specifies the max number of sentences in summary. While sumy can be used with plain text files, this tutorial will only cover HTML inputs.
def summarize_html(url: str, sentences_count: int, language: str = 'english') -> str:
"""
Summarizes text from URL
Inputs
----------
url: URL for full text
sentences_count: specifies max number of sentences for return value
language: specifies language of text
Return
----------
summary of text from URL
"""
parser = HtmlParser.from_url(url, Tokenizer(language))
stemmer = Stemmer(language)
summarizer = Summarizer(stemmer)
summarizer.stop_words = get_stop_words(language)
summary = ''
for sentence in summarizer(parser.document, sentences_count):
if not summary:
summary += str(sentence)
else:
summary += ' ' + str(sentence)
return summary
summarize_html_example.py hosted with ? by GitHub
The output shows the top 10 most important sentences in the article, which acts as a summary.
Here’s an example using the Wikipedia entry for Automatic summarization per the sumy Github page:
url = 'https://en.wikipedia.org/wiki/Automatic_summarization'
summarize_html(url, 10)
First, you need sign up and get an API key, which is easily done here . After signing up, an API key will automatically get generated and shown on the next screen. While there is a Python client library, I opted to create my own functions since it’s a straight forward API.
This article will cover two endpoints from the API:
def news_api_request(url: str, **kwargs) -> list:
"""
Sends GET request to News API endpoint
Inputs
----------
url: full URL for endpoint
kwargs: please refer to
News API documentations:
https://newsapi.org/docs/endpoints/
(apiKey argument is required)
Return
----------
list containing data for each article in response
"""
params = kwargs
res = requests.get(url, params=params)
articles = res.json().get('articles')
return articles
news_api_request_function.py hosted with ? by GitHub
def summarize_news_api(articles: list, sentences_count: int) -> list:
"""
summarizes text at URL for each element of articles dict
(return value from news_api_request) and adds a new element
articles dict where the key is 'summary' and the value is
the summarized text
Inputs
----------
articles: list of dict returned from news_api_request()
sentences_count: specifies max number of sentences for
return value
Return
----------
articles list with summary element added to each dict
"""
for article in articles:
summary = summarize_html(article.get('url'), sentences_count)
article.update({'summary': summary})
return articles
summarize_news_api_function.py hosted with ? by GitHub
The summarize_news_api function iterates through each article, and passes the article’s URL to the summarize_html function. Each dict in articles gets updated with a new element for the summary.
The following code snippet is an example of using news_api_request and summarize_news together, to summarize the articles in the response from /v2/top-headlines endpoint.
url = 'https://newsapi.org/v2/top-headlines/'
articles = news_api_request(url, apiKey=api_key, sortBy='publishedAt', country='us')
summaries = summarize_news_api(articles)
print(summaries[0])
news_api_request_example.py hosted with ? by GitHub
If you run the above code, you will print a dict, representing the first article, with key/value pairs in the format shown below:
{'source': {'id': None, 'name': None},
'author': '',
'title': '',
'description': '',
'url': '',
'urlToImage': '',
'publishedAt': '',
'content': '',
'summary': ''}
news_api_request_response.py hosted with ? by GitHub
Now that you have learned how to pull data from News API, and summarize the text, it’s time to build an app that meets the following criteria:
Streamlit is a super intuitive front end solution for Python users. It lends itself well to creating prototypes and simple tools, which is why I thought it would be great for this project.
Streamlit will be introduced by building the front end of the app specified in the previous section.
import streamlit as st
st.title('News Summarizer')
Run the app:
A browser window should pop up, and look like this:

import streamlit as st
st.title('News Summarizer')
# Gives option between top stories and search term
search_choice = st.sidebar.radio('', options=['Top Headlines', 'Search Term'])
# Takes user input for max number of sentences per summary
sentences_count = st.sidebar.slider('Max sentences per summary:', min_value=1,
max_value=10,
value=3)
news_app_1.py hosted with ? by GitHub
Line 6 creates radio buttons to allow users to select which endpoint to search. The first argument is a label for the radio button cluster, which I left as a blank str since the ratio buttons are descriptive enough for this app. The second argument lets you pass the options for radio buttons as a list. The user input is then saved to search_choice as a str, which makes it simple to use throughout the app. In this example, the first element of the list is the default value.
Line 9 creates a slider input widget, which gives users the ability to specify the length of the summaries. Again, the first argument is a label for the widget. The remaining arguments define the range of the slider, and the default value. The user input is saved to sentences_count as an int.
When you run the app, you should see something like this:
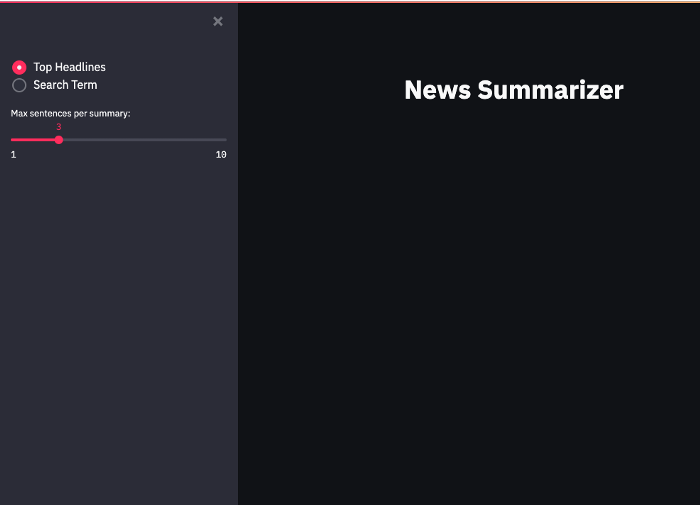
As you can see, the widgets appear on a collapsable sidebar. If you replace st.sidebar.radio with st.radio, the widget will appear under the title.
The next features will depend on whether the user selects ‘Top Headlines’ or ‘Search Term’. If the ‘Top Headlines’ is selected, the user needs to have the option to select a category. If ‘Search Term’ is selected, the user will need to be able to enter a search term.
import streamlit as st
st.title('News Summarizer')
# Gives option between top stories and search term
search_choice = st.sidebar.radio('', options=['Top Headlines', 'Search Term'])
# Takes user input for max number of sentences per summary
sentences_count = st.sidebar.slider('Max sentences per summary:', min_value=1,
max_value=10,
value=3)
# If user selects 'Top Headlines', a category dropdown will appear
if search_choice == 'Top Headlines':
category = st.sidebar.selectbox('Category:', options=['business',
'entertainment',
'general',
'health',
'science',
'sports',
'technology'], index=2)
st.write(f'you will see articles about {category} here')
# This is where we will call get_top_headlines()
# If user selects 'Search Term', a text input box will appear
elif search_choice == 'Search Term':
search_term = st.sidebar.text_input('Enter Search Term:')
if not search_term:
st.write('Please enter a search term =)')
else:
st.write(f'you will see articles about {search_term} here')
# This is where you will call search_articles()
streamlit_news_widgets.py hosted with ? by GitHub
As you can see, the flow of the app is defined by the value of search_choice, which is used in the conditionals on lines 14 and 27. If the user selects ‘Top Headlines’, a dropdown will appear with options for categories. The options passed to st.sidebar.selectbox come from the NewsAPI documentation. The index argument specifies which element of the list to use as default, and I thought ‘general’ made sense.
If the user selects ‘Search Term’, a text box will appear to take user input. I added a conditional statement to prompt user for input if the text input box is empty. This helps to avoid errors when the API calls are added.
You should see something like this when you run the app:
Live preview of News Summarizer
This shows you the raw shell of the app, and it appears to be meeting the criteria set up above. Now you just need to incorporate the functions from earlier to hit News API and summarize the text.
I like to use a separate file for functions so that the Streamlit app stays clean. The below snippet shows five functions needed for the app. The first three functions, summarize_html ,news_api_request, and summarize_news_api are the same ones we used above. I added two new functions, search_articles and get_top_headlines, which both pass hardcoded endpoints to the news_api_request function to help simplify the code.
from sumy.parsers.html import HtmlParser
from sumy.nlp.tokenizers import Tokenizer
from sumy.summarizers.lsa import LsaSummarizer as Summarizer
from sumy.nlp.stemmers import Stemmer
from sumy.utils import get_stop_words
import requests
def summarize_html(url: str, sentences_count: int, language: str = 'english') -> str:
"""
Summarizes text from URL
Inputs
----------
url: URL for full text
sentences_count: specifies max number of sentences for return value
language: specifies language of text
Return
----------
summary of text from URL
"""
parser = HtmlParser.from_url(url, Tokenizer(language))
stemmer = Stemmer(language)
summarizer = Summarizer(stemmer)
summarizer.stop_words = get_stop_words(language)
summary = ''
for sentence in summarizer(parser.document, sentences_count):
if not summary:
summary += str(sentence)
else:
summary += ' ' + str(sentence)
return summary
def news_api_request(url: str, **kwargs) -> list:
"""
Sends GET request to News API endpoint
Inputs
----------
url: full URL for endpoint
kwargs: please refer to
News API documentations:
https://newsapi.org/docs/endpoints/
(apiKey argument is required)
Return
----------
list containing data for each article in response
"""
params = kwargs
res = requests.get(url, params=params)
articles = res.json().get('articles')
return articles
def summarize_news_api(articles: list, sentences_count: int) -> list:
"""
summarizes text at URL for each element of articles dict
(return value from news_api_request) and adds a new element
articles dict where the key is 'summary' and the value is
the summarized text
Inputs
----------
articles: list of dict returned from news_api_request()
sentences_count: specifies max number of sentences for
return value
Return
----------
articles list with summary element added to each dict
"""
for article in articles:
summary = summarize_html(article.get('url'), sentences_count)
article.update({'summary': summary})
return articles
def search_articles(sentences_count: int, **kwargs) -> list:
"""
Sends GET request to News API /v2/everything endpoint,
and summarizes data at each URL
Inputs
----------
sentences_count: specifies max number of sentences
for return value
kwargs: see News API
documentation:
https://newsapi.org/docs/endpoints/everything
Return
----------
list where each element is a dict containing info about a single article
"""
url = 'https://newsapi.org/v2/everything/'
articles = news_api_request(url, **kwargs)
return summarize_news_api(articles, sentences_count)
def get_top_headlines(sentences_count: int, **kwargs) -> list:
"""
Sends GET request to News API /v2/top-headlines endpoint,
and summarizes data at each URL
Inputs
----------
sentences_count: specifies max number of sentences for return value
kwargs: see News API
documentation:
https://newsapi.org/docs/endpoints/top-headlines
Return
----------
list where each element is a dict containing info
about a single article
"""
url = 'https://newsapi.org/v2/top-headlines/'
articles = news_api_request(url, **kwargs)
return summarize_news_api(articles, sentences_count)
app_functions.py hosted with ? by GitHub
import os
from app_functions import get_top_headlines, search_articles
import streamlit as st
API_KEY = os.environ['NEWS_API_KEY']
st.title('News Summarizer')
search_choice = st.sidebar.radio('', options=['Top Headlines', 'Search Term'])
sentences_count = st.sidebar.slider('Max sentences per summary:', min_value=1,
max_value=10,
value=3)
if search_choice == 'Top Headlines':
category = st.sidebar.selectbox('Search By Category:', options=['business',
'entertainment',
'general',
'health',
'science',
'sports',
'technology'], index=2)
summaries = get_top_headlines(sentences_count, apiKey=API_KEY,
sortBy='publishedAt',
country='us',
category=category)
elif search_choice == 'Search Term':
search_term = st.sidebar.text_input('Enter Search Term:')
if not search_term:
summaries = []
st.write('Please enter a search term =)')
else:
summaries = search_articles(sentences_count, apiKey=API_KEY,
sortBy='publishedAt',
q=search_term)
for i in range(len(summaries)):
st.title(summaries[i]['title'])
st.write(f"published at: {summaries[i]['publishedAt']}")
st.write(f"source: {summaries[i]['source']['name']}")
st.write(summaries[i]['summary']))
news_summarizer_app.py hosted with ? by GitHub
In the above code, line 2 imports the functions from app_function.py. On line 23, get_top_headlines is called, which calls the /v2/everything endpoint. This corresponds to the user selecting ‘Top Headlines’ for search_choice.
On line 36, search_articles is called, which calls the /v2/everything endpoint. This corresponds to the user selecting ‘Search Term’ for search_choice.
On line 40, the app will loop through summaries, and write out selected information that the app needs to display. In this example, the app will display title, date/time of publication, source name, and the summary that we generated in the preceding steps.
Finally, you can run the finished app:
streamlit run news_summarizer_app.py
You can see the full project here.
I think this app is a pretty good start, but there are a number of ways to make it better. Here are a few improvements I thought about:
You just learned how to build a basic news summarization app in Python, using Streamlit, News API, and sumy. I hope this gives you some ideas for new projects. Thanks for reading.
LATEST NEWS
WHAT'S TRENDING


Data Science
5 Imaginative Data Science Projects That Can Make Your Portfolio Stand Out
OCT 05, 2022

SOURCE: WWW.DISCOVERDATASCIENCE.ORG/
AUG 14, 2023



SOURCE: MEDIUM.DATADRIVENINVESTOR.COM
OCT 05, 2022

SOURCE: VENTURESAFRICA.COM
OCT 05, 2022