





New AI model shows how machines can learn from vision, language and sound together
SOURCE: GEEKWIRE.COM
APR 16, 2022
Most of us have watched television with the sound turned off at one time or another. While it’s usually possible to follow the story at least to some degree, the absence of an audio track tends to limit our ability to fully appreciate what’s taking place.
Similarly, it’s easy to miss a lot of information just listening to the sounds coming from another room. The multimodality of combining image, sound and other details greatly enhances our understanding of what’s happening, whether it’s on TV or in the real world.
The same appears to be true for artificial intelligence. A new question answering model called MERLOT RESERVE enables out-of-the-box prediction, revealing strong multimodal commonsense understanding. It was recently developed by a team from the Allen Institute for Artificial Intelligence (AI2), University of Washington and University of Edinburgh.
Part of a new generation of AI applications that enable semantic search, analysis, and question answering (QA), the system was trained by having it “watch” 20 million YouTube videos. The capabilities demonstrated are already being commercialized by startups such as Twelve Labs and Clipr.
MERLOT RESERVE (RESERVE for short), stands for Multimodal Event Representation Learning Over Time, with Re-entrant Supervision of Events, and is built on the team’s previous MERLOT model. It was pretrained on millions of videos, learning from the combined input of their images, audio and transcriptions. Individual frames allow the system to learn spatially while video-level training gives it temporal information, training it about the relationships between elements that change over time.
“The way AI processes things is going to be different from the way that humans do,” said computer scientist and project lead Rowan Zellers. “But there are some general principles that are going to be difficult to avoid if we want to build AI systems that are robust. I think multimodality is definitely in that bucket.”

Rowan Zellers, researcher at the University of Washington and Allen Institute of Artificial Intelligence.
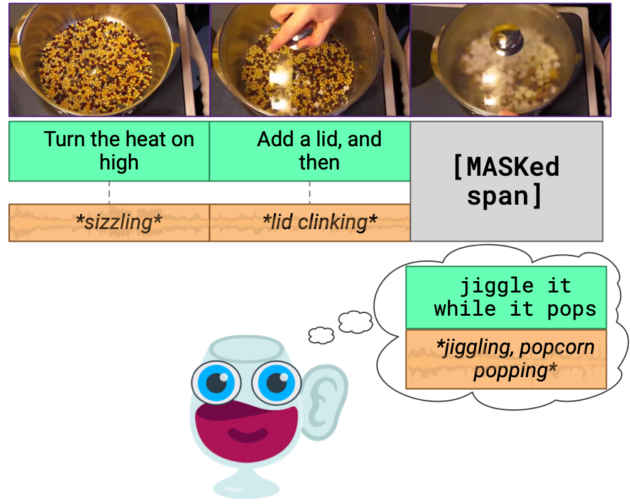
Because we live in a dynamic world, the team wanted to explore building machines that learn from vision, language, and sound together. In one of the paper’s examples, someone is seen cooking popcorn. From the images and dialogue alone, we can imagine the sounds that might accompany them. The sound of uncooked kernels moving about on a pot’s metallic surface might eventually change to energetic ‘pops’ as they burst into fluffy white popcorn.
Such prediction is known as “learning from reentry” where time-locked correlations enable one modality to educate others. This has been hypothesized by some developmental psychologists to be how we learn visual and world knowledge, often without a teacher. It’s also the basis of RESERVE’s name: Re-entrant Supervision of Events.
The model is trained on 40-second-long video segments, where snippets of text and audio are “masked” from the system. RESERVE then learns by selecting the correct masked-out snippet from four multiple-choice options. This is followed with selecting from four possible rationales to justify its answer.
This approach not only allowed RESERVE to achieve state-of-the-art results from its semi-supervised training, but to make strong zero-shot predictions as well. In this case, one example of zero-shot prediction might be a question like “What is the person doing?” This can be manually, or automatically rewritten as a statement like “The person is [MASK].” The model then does multiple-choice prediction over a set of provided options like “cooking popcorn” or “eating popcorn.”
RESERVE was fine-tuned on several large-scale datasets used for cognition-level visual understanding: VCR, TVQA and Kinetics-600. RESERVE exhibited state-of-the-art performance, besting prior work by 5%, 7% and 1.5% respectively. By incorporating audio, the model achieves 91.1% accuracy on Kinetics-600.
VCR (Visual Commonsense Reasoning) is a large-scale dataset with no audio which is used for cognition-level visual understanding. TVQA is a large-scale video QA dataset based on six popular TV shows (Friends, The Big Bang Theory, How I Met Your Mother, House M.D., Grey’s Anatomy, and Castle). Finally, Kinetics-600 is a collection of 650,000 video clips that cover hundreds of human action classes.
According to the study’s paper, which will be presented at IEEE/CVF International Conference on Computer Vision and Pattern Recognition in June, RESERVE shows significant performance improvements over competing models. For instance, it requires one-fifth the floating-point operations used by the VisualBERT multimodal model.
The project team anticipates that video-pretrained models might someday assist low-vision or deaf users or be used for mining insights about video-watching trends. However, they also recognize the datasets used to train RESERVE introduce inevitable biases which needs to be addressed.
Beyond just the words being spoken, audio can provide a lot of additional contextual information. This shouldn’t come as a surprise for us, based on our own experiences, but it’s fascinating that the performance of the AI can be significantly improved by this as well. That may be because in synchronizing the extra information, new statistical correlations can be made.
“Audio is a lot of things. It’s not just voice, but sound effects too and hearing those sound effects does improve your understanding of the world,” Zellers observed.
“Another thing is tone of voice, the human communication dynamics. If you just look at the words, without the audio context, you miss a lot. But if someone says that word with a specific emotion, then the model can do a lot better. And actually, we find it does.”
MERLOT and RESERVE are part of AI2’s Mosaic team which focuses on developing systems that can measure and develop machine commonsense. Machine commonsense has been an area of interest in the field of artificial intelligence for decades. Being able to factor and anticipate real world relationships between different objects and processes would make our AI tools far more useful to us.
However, it’s not enough to simply load a bunch of facts and rules about how the world works into a system and expect it to work. The world is simply too complex to do this. We, on the other hand, learn by interacting with our environment through our various senses from the moment we’re born. We incrementally build an understanding about what happens in the world and why. Some machine commonsense projects use a similar approach. For MERLOT and RESERVE, incorporating additional modalities provides extra information much as our senses do.
“I think medium and long term, what I’m really excited about is AI that converses with us in multiple modalities like audio and gesture so it can make connections about the stuff we’re doing,” Zellers observed. The authors of the project paper, “MERLOT RESERVE: Neural Script Knowledge through Vision and Language and Sound” are Rowan Zellers, Jiasen Lu, Ximing Lu, Youngjae Yu, Yanpeng Zhao, Mohammadreza Salehi, Aditya Kusupati, Jack Hessel, Ali Farhadi, and Yejin Choi. A demo for RESERVE can be found at AI2.

Richard Yonck is a Seattle-based futurist and keynote speaker who explores future trends and emerging technologies, identifying their potential impacts on business and society. He’s written for dozens of national and global publications and is author of two books about the future of artificial intelligence, Heart of the Machine and Future Minds. Follow him on Twitter @ryonck and reach him at futurist@richardyonck.com.
LATEST NEWS
Artificial Intelligence
Eerily realistic: Microsoft’s new AI model makes images talk, sing
APR 20, 2024
WHAT'S TRENDING


Data Science
5 Imaginative Data Science Projects That Can Make Your Portfolio Stand Out
OCT 05, 2022

Similar articles you can read
Eerily realistic: Microsoft’s new AI model makes images talk, sing
SOURCE: INTERESTINGENGINEERING.COM
APR 20, 2024
80% of AI decision makers are worried about data privacy and security
SOURCE: ARTIFICIALINTELLIGENCE-NEWS.COM
APR 17, 2024
AI Is Set To Change Fertility Treatment Forever
SOURCE: HTTPS://CODEBLUE.GALENCENTRE.ORG/
NOV 06, 2023
AI-empowered system may accelerate laparoscopic surgery training
SOURCE: HTTPS://WWW.NEWS-MEDICAL.NET/
NOV 06, 2023
Here’s Everything You Can Do With Copilot, the Generative AI Assistant on Windows 11
SOURCE: HTTPS://WWW.WIRED.COM/
NOV 05, 2023
Tongyi Qianwen, An AI Model Developed By Alibaba, Has Been Upgraded, And Industry-specific Models Have Been Released
SOURCE: HTTPS://WWW.BUSINESSOUTREACH.IN/
OCT 31, 2023