





Hybrid AI-powered computer vision combines physics and big data
SOURCE: HTTPS://WWW.SCIENCEDAILY.COM/
AUG 14, 2023
MIT Researchers Developed A Machine-Learning Model To Generate Extremely Realistic Synthetic Data That Can Train Another Model For Downstream Vision Tasks
SOURCE: MARKTECHPOST.COM
MAR 20, 2022
Many machine learning tasks require high-quality data, such as assessing damage in a satellite that negatively affects a model’s performance. Datasets can cost millions of dollars to create if useable data exists, and even the best datasets sometimes contain biases that negatively impact a model’s performance.
Many scientists have been working to answer an intriguing question working with synthetic data sampled from a generative model instead of real data. A generative model is a machine-learning model that requires significantly less memory to keep or share than a dataset. The range and quality of generative models have improved dramatically in recent years.
Synthetic data has the ability to get around some of the privacy and usage rights problems that limit how actual data may be distributed. A generative model could potentially be updated to eliminate particular attributes, such as race or gender, to overcome biases in traditional datasets.
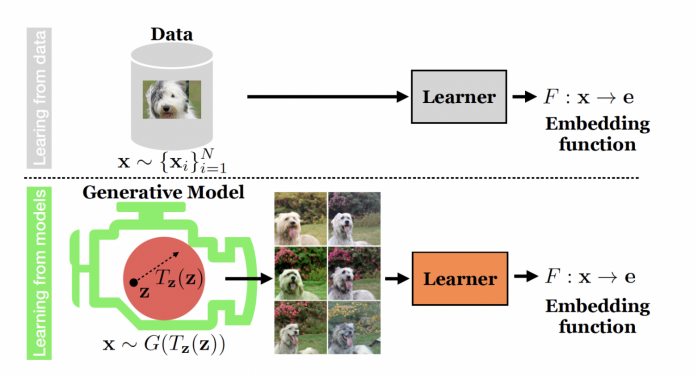
New research by MIT Team develops a method for training a machine learning (ML) model that, rather than requiring a dataset, employs a particular form of ML model to generate exceptionally realistic synthetic data that can train another model for downstream vision tasks.
Their findings suggest that a contrastive representation learning model trained solely on synthetic data may develop visual representations comparable to, if not superior to, those learned from actual data.
After a generative model has been trained on actual data, it can generate synthetic data that is indistinguishable from the original. The training method gives the generative model millions of photos containing objects in a specific class (such as vehicles or cats), after which it learns how to generate comparable objects.
This pretrained generative model can then be used to generate a steady stream of unique and realistic images based on those in the model’s training dataset by just turning a switch.

https://ali-design.github.io/GenRep/
The team explains that generative models are more beneficial since they learn how to modify the underlying data that they are trained on. For example, a model trained on photos of vehicles can “imagine” how a car would look in new scenarios — situations it hasn’t seen before — and then generate images representing the car in different positions, colors, or sizes.
Multiple views of the same image are necessary for contrastive learning, which involves exposing a machine-learning model to many unlabeled images to learn whether pairs are similar or different.
To enable two models to work together automatically, the researchers linked a pre-trained generative model to a contrastive learning model. They believe that a generative model can aid the contrastive method in learning more accurate representations because the generative model can provide multiple perspectives on the same object.
The team discovered that their model performs better when compared to a number of different image classification models trained using real data.
A generative model has the advantage of being able to generate an endless number of samples in principle. As a result, the researchers looked at how the model’s performance was affected by the number of samples used. They discovered that increasing the number of unique samples generated in some cases resulted in even more benefits. These generative models are already trained, are available in online repositories, and can be used by anyone.
The team remarks that these models can reveal source data in some situations, posing a privacy concern. Furthermore, if not adequately trained, they can accentuate biases in their trained datasets.
The team plans to address this issue in the coming future. In addition, they also aim to explore methods to use this technique to generate corner cases that could help machine learning models improve.
Most of the time, real data cannot be used to learn about corner cases. For example, if researchers develop a computer vision model for a self-driving car, genuine data would not include examples of a dog and its owner sprinting down a highway. Therefore the model would never learn what to do in this scenario. In some high-stakes circumstances, synthetically generating that corner case data could boost the performance of machine learning models.
Paper: https://openreview.net/pdf?id=qhAeZjs7dCL
Github: https://github.com/ali-design/GenRep
Project: https://ali-design.github.io/GenRep/
Reference: https://news.mit.edu/2022/synthetic-datasets-ai-image-classification-0315
Tanushree Shenwai http://www.marktechpost.com
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
LATEST NEWS
WHAT'S TRENDING


Data Science
5 Imaginative Data Science Projects That Can Make Your Portfolio Stand Out
OCT 05, 2022

SOURCE: HTTPS://WWW.SCIENCEDAILY.COM/
AUG 14, 2023


SOURCE: INDIANEXPRESS.COM
OCT 24, 2022



