





White Castle to deploy voice-enabled digital signage in US
SOURCE: HTTPS://WWW.VERDICTFOODSERVICE.COM/
OCT 04, 2023
Meta AI’s LegoNN Builds Decoder Modules That Are Reusable Across Diverse Language Tasks Without Fine-Tuning
SOURCE: SYNCEDREVIEW.COM
JUN 20, 2022
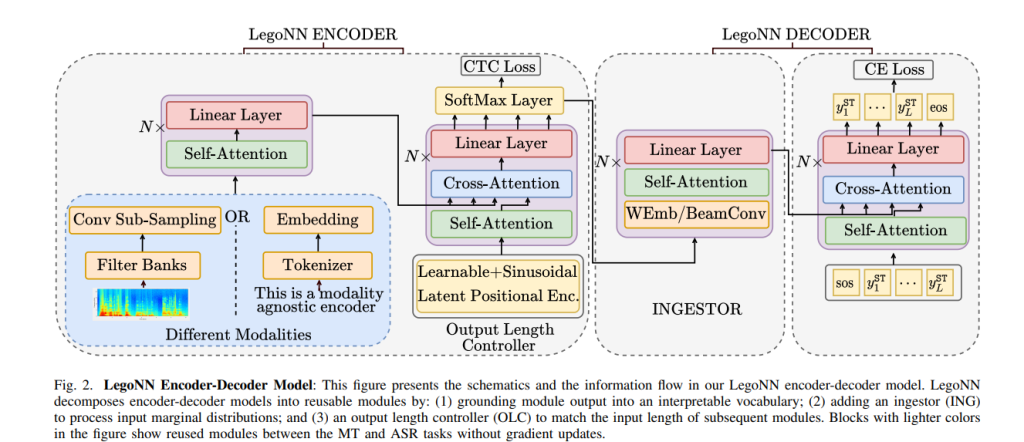
Encoder-decoder models have become the preferred approach for a wide range of language-related tasks. Although some common logical functions are shared between different tasks, most contemporary encoder-decoder models are trained end-to-end for a specified task. This specialization increases the compute burden during training and results in less generally interpretable architectures.
Meta AI researchers address these issues in the new paper LegoNN: Building Modular Encoder-Decoder Models, proposing a procedure for building encoder-decoder architectures with decoder modules that can be shared across sequence generation tasks such as machine translation (MT) and automatic speech recognition (ASR) without requiring finetuning or suffering significant performance reductions.

Introducing modularity to encoder-decoder architectures enables reusability, which can save computational resources and benefit under-resourced tasks by utilizing shareable components from higher-resourced tasks.

The LegoNN encoders enable an interpretable interface by outputting a sequence of distributions over a discrete vocabulary derived from the final output labels. A novel Connectionist Temporal Classification (CTC) loss is employed on these outputs. The researchers also build a modality agnostic encoder for sequence prediction tasks, which leverages an output length controller (OLC) unit that uses cross-attention between two groups of transformer layers to enable working with fractional length ratios between inputs and outputs of the same module. LegoNN can thus train decoders and intermediate modules between different tasks and domains without jointly training for the tasks or requiring finetuning.

Given a typical German to English (De-En) MT system, the LegoNN framework can be used to build additional ASR and MT language systems without constructing a new dedicated decoder. Developers can instead build only a new encoder system and reuse the existing decoder module.

In their empirical study, the team evaluated the feasibility of reusing LegoNN modules on various ASR and MT tasks, where it achieved competitive performance, matching or beating baseline models. Their LegoNN decoder trained for De-En WMT (Workshop on Machine Translation) tasks was able to effectively replace an ASR decoder module without any performance drop, and provided better generation quality when applied to Romanian to English (Ro-En) WMT tasks.
The team notes that reusable libraries are common in software development and hopes their paper can help bring a similar paradigm to sequence-to-sequence neural models. Their future research will explore combining the flexibility of LegoNN models with the proven performance of encoder pretraining methods such as those used in Google’s BERT large language model, and exploring LegoNN’s zero-shot learning capabilities for speech translation scenarios that rely on a combination of ASR and MT modules.
The paper LegoNN: Building Modular Encoder-Decoder Models is on arXiv.
LATEST NEWS
Augmented Reality
Hi-tech smart glasses connecting rural and remote aged care residents to clinicians
NOV 20, 2023
WHAT'S TRENDING


Data Science
5 Imaginative Data Science Projects That Can Make Your Portfolio Stand Out
OCT 05, 2022

SOURCE: HTTPS://WWW.VERDICTFOODSERVICE.COM/
OCT 04, 2023
SOURCE: HTTPS://RESEARCH.AIMULTIPLE.COM/
JUL 12, 2023
SOURCE: HTTPS://RESEARCH.AIMULTIPLE.COM/
JUL 11, 2023


SOURCE: TECHCRUNCH.COM
OCT 27, 2022


SOURCE: THEHINDU.COM
OCT 16, 2022