





CMU Researchers Introduce the Open Whisper-Style Speech Model: Advancing Open-Source Solutions for Efficient and Transparent Speech Recognition Training
SOURCE: HTTPS://WWW.MARKTECHPOST.COM/
OCT 03, 2023
Google AI sparks a revolution in Machine Learning.
SOURCE: MACHINE-LEARNING-MADE-SIMPLE.MEDIUM.COM/
MAY 07, 2022
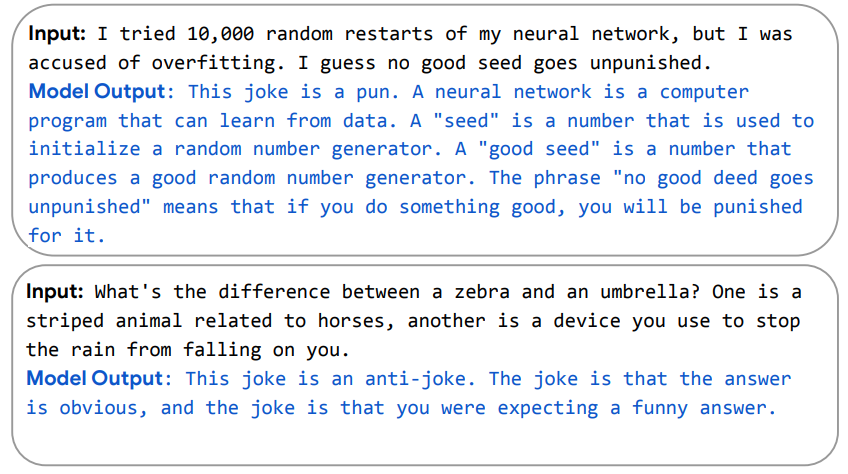
Unless you’re living under a rock, you know of Google’s Pathways Language Model (PaLM), “a 540-billion parameter, dense decoder-only Transformer model trained with the Pathways system”. People are going insane over the functionality that the team was able to develop. One of the cases that has gained a lot of notoriety online is PaLMs ability to explain jokes-

This was something I even mentioned in my article The Truth Behind Google’s Machine Learning Research
This ability to explain jokes is an indication that the PaLM model has a deeper understanding of meaning and sentence structure, and relationships between words. If I had to guess, this was made possible by the attention mechanism and the scale of the model itself. However, I wanted to focus on something that has not been getting as much attention- Pathways, The underlying architecture that made this possible.
This not going to be a standard article, talking about the specifics of the model. Instead, I will cover the design choices that make this architecture so interesting. Some of those are very unique and might be huge in AI in the coming decades. To understand this, let’s understand the amazing Pathways system, which debuted in the writeup, Introducing Pathways: A next-generation AI architecture.
In all the hype around PaLM, people have not spent enough time understanding Google’s Pathways. But, when you do look into it, you will see that it is nothing short of a revolution. I’m not exaggerating.

Regular readers know that I don’t use clickbait or hype. The article referred to, Machine Learning for the Metaverse. Why Meta’s AI Lab is so random.
The inspiration for the infrastructure is our brain. I know every Neural Network says that, but this is much closer than others. How? Think back to how our brains work. We have a ton of neurons with hundreds of trillions of potential wiring. As we learn certain skills, neurons fire together and build certain pathways. These pathways solidify as we practice. The next time we use that skill, our pathways will fire up, allowing us to remember that skill.
Researchers at Google did something similar. They built a giant model with tons of neurons and connections. They trained that one model on multiple tasks. And they implemented Sparse Activation so to save resources. It’s hard to argue with the results.

Keep in mind, that the y-axis is improvement over SOTA (State of the Art). This is all one model. Insane
Theese implementation decisions are uncommon when compared to the way Machine Learning is conducted now. The researchers at Google raise a lot of points about why their approach is better than what is being done right now. Let’s cover these, and talk about how they add another dimension to the current discourse around Deep Learning. To do that, let’s first list out what makes Pathways closer to our own way of learning.
There are several design choices that make the Pathways infrastructure much closer to our own minds. The big ones include
Let’s explore this in more detail.
In normal Machine Learning, we take a model architecture and train it from Scratch to teach it our specific task. But Google researchers are like edgy teens and are terrified of being seen as normal. They strive to express their individuality.
Pathways will enable us to train a single model to do thousands or millions of things
-From the Pathways introduction article.
Instead, they train the same model on many different tasks. The same model. Not the same architecture. The exact same model. Imagine if I trained the model I worked on to detect Parkinson’s Disease to also forecast supplier risk scores (my work at ForeOptics).

What is the logic behind this? Let’s take a simple example. We know Cristiano Ronaldo plays Football. To be the freak of nature he is, he takes his physical conditioning very seriously. Thus, when it comes to activities like Running and Jumping, he is going to be much better than your average Joe, even though this is not his focus. In my more advanced readers, this might be ringing a few bells. You have one question-
Transfer Learning is the practice of taking Large Models trained on generic tasks, and then using the insights gained from that to train a related model on a related example. The idea is that the knowledge from the related tasks will “carry over” to our new task. In our earlier example, Ronaldo’s training in Football allows him to also be a good Runner.
A visualization of the Pathways architecture. We have a many tasks all being taught to the same model.
Pathways is different because they take this to the next level. When they say millions of things, they mean it. Pathways is trained on tasks that are almost completely unrelated to each other. This would be like teaching Ronaldo Differential Equations, while also training him to be an archeologist, as he was prepping to play Football. This is much closer to AGI, and what has allowed the PaLM model to develop its much deeper understanding of meaning and language. It is also much closer to how we learn.

Examples that showcase PaLM 540B 1-shot performance on BIG-bench tasks: labeling cause and effect, conceptual understanding, guessing movies from emoji, and finding synonyms and counterfactuals.
Senses are how we perceive the world. This is often overlooked in Machine Learning (especially if you’re primarily a statistical analyst like me) but senses literally determine your input. One of the biggest challenges in converting Machine Learning research into working solutions is in translating the input data into valuable information that can be analyzed. Preprocessing is a big deal. This is why people say that ML is mostly data cleaning and preprocessing.
For AI purposes, each Data Source can be treated as a sense. Most ML applications use limited sources and typically work on only one kind of data (NLP, Computer Vision, Behavior, etc). As you can see in the following passage, Pathways will not be doing this.

Adding in more sources to reduce error is something I’ve been saying for a long time. Way before it was fashionable. I’m glad to see that people are finally acknowledging it.
This mimics the way we interact with the world. We learn by interacting with objects using both our physical (touch, taste, smell, etc.) and mental (creating models, theories, abstractions) senses. Integrating more senses is much harder, but the pay-off is worth it. As the paper, “Accounting for Variance in Machine Learning Benchmarks” showed us, adding more sources of variance improves estimators. You can read my breakdown of the paper here, or watch the following YouTube video for a quick explanation. Either way, don’t miss out on this paper.
This is probably the most interesting idea to me in the entire paper. To understand why this is so cool, think back to how Neural Networks work. When we train them, input flows through all the neurons, both in the forward and backward passes. This is why adding more parameters to a Neural Network adds to the cost exponentially.
Watch the Neural Networks series by 3Blue1Brown for a more thorough explanation.
If you don’t know how Neural Networks work, read the article How to Learn Machine Learning in 2022. That goes into depth with a step-by-step plan on how to learn Machine Learning the right way. The course plan uses free resources, so you can learn without breaking the bank. Now let’s get into why Sparse Activation is a potential game-changer.
Adding more neurons to our network allows for our model to learn from more complex data (like data from multiple tasks and data from multiple senses). However, this adds a lot of computational overhead.

PaLM also translates code. They really made their model do everything.
Sparse Activation allows for a best of both worlds scenario. Adding a lot parameters allows for our computation power. PaLM does have 540 Billion Parameters. However, for any given task, only a portion of the network is activated. This allows the network to learn and get good at multiple tasks, without being too costly.

Turns out that Millions of Years of Evolutionary Algorithms are much better at learning than minute algorithms created 20 years ago. Who would have thought?
The conception kind of reminds me of a more modern twist on the Mixture of Experts learning protocol. Instead of deciphering which expert can handle the task best, we are instead routing the task to the part of the neural network that handles it best. This is similar to our brain, where different parts of our brain are good at different things.
Sparse Activation is such a cheat code that it provides much cheaper training while giving the same performance. Take a look at this quote from the Pathways writeup-
For example, GShard and Switch Transformer are two of the largest machine learning models we’ve ever created, but because both use sparse activation, they consume less than 1/10th the energy that you’d expect of similarly sized dense models — while being as accurate as dense models.
This shows itself with the PaLM model. Adding more parameters allows for a much greater ability when it comes to tackling challenges. Inferring the nature of the task given, training for it, and being handle to handle it are all expensive procedures. Sparse Activation allows the model to handle all this better.

A pretty nifty visualization of the increase in capabilities upon adding more parameters for the PaLM model.
Clearly, you can now see how Pathways will be a game-changer for AI research in the upcoming decade. It combines ideas from neuroscience, Machine Learning, and Software Engineering with the scale of Large Language Models to create something exceptional. The training protocols will be era-defining, even as people create other, better ML models.
That’s it for this article. I’ll end with an interesting observation. We can see that PaLM needed much fewer parameters for Code Completion than Logical Inference. Most ML courses/gurus teach you the former without explaining the latter. This is setting yourself up for failure. Look at the following message I received-

The reason I stress the basics is that they will never be replaced. Subscribe to my newsletter, to make sure you don’t miss out on the foundational skills. Details below.
To help me write better articles and understand you fill out this survey (anonymous). It will take 3 minutes at most and allow me to improve the quality of my work. Please do use my social media links to reach out with any additional feedback. All feedback helps me improve.

For Machine Learning, a base in Software Engineering is crucial. It will help you conceptualize, build, and optimize your ML. My daily newsletter, Coding Interviews Made Simple covers topics in Algorithm Design, Math, Recent Events in Tech, Software Engineering, and much more to make you a better developer. I am currently running a 20% discount for a WHOLE YEAR, so make sure to check it out.

I created Coding Interviews Made Simple using new techniques discovered through tutoring multiple people into top tech firms. The newsletter is designed to help you succeed, saving you from hours wasted on the Leetcode grind. You can read the FAQs and find out more here
Feel free to reach out if you have any interesting jobs/projects/ideas for me as well. Always happy to hear you out.
For monetary support of my work following are my Venmo and Paypal. Any amount is appreciated and helps a lot. Donations unlock exclusive content such as paper analysis, special code, consultations, and specific coaching:
Venmo: https://account.venmo.com/u/FNU-Devansh
Paypal: paypal.me/ISeeThings
Use the links below to check out my other content, learn more about tutoring, or just to say hi. Also, check out the free Robinhood referral link. We both get a free stock (you don’t have to put any money), and there is no risk to you. So not using it is just losing free money.
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
If you’re preparing for coding/technical interviews: https://codinginterviewsmadesimple.substack.com/
Get a free stock on Robinhood: https://join.robinhood.com/fnud75
LATEST NEWS
Augmented Reality
Hi-tech smart glasses connecting rural and remote aged care residents to clinicians
NOV 20, 2023
WHAT'S TRENDING


Data Science
5 Imaginative Data Science Projects That Can Make Your Portfolio Stand Out
OCT 05, 2022

SOURCE: HTTPS://WWW.MARKTECHPOST.COM/
OCT 03, 2023
SOURCE: HTTPS://NEWS.MIT.EDU/
AUG 17, 2023
SOURCE: HTTPS://WWW.SCIENCEDAILY.COM/
AUG 21, 2023
SOURCE: HTTPS://WWW.SCIENCEDAILY.COM/
AUG 17, 2023
SOURCE: HTTPS://WWW.SCIENCEDAILY.COM/
AUG 07, 2023
SOURCE: HTTPS://WWW.INDIATODAY.IN/TECHNOLOGY/NEWS/STORY/69-MILLION-GLOBAL-JOBS-TO-BE-CREATED-IN-NEXT-FIVE-YEARS-AI-AND-MACHINE-LEARNING-ROLES-TO-GROW-IN-INDIA-2367326-2023-05-02
JUN 28, 2023