





CMU Researchers Introduce the Open Whisper-Style Speech Model: Advancing Open-Source Solutions for Efficient and Transparent Speech Recognition Training
SOURCE: HTTPS://WWW.MARKTECHPOST.COM/
OCT 03, 2023
Demystifying deep reinforcement learning
SOURCE: VENTUREBEAT.COM
SEP 04, 2021
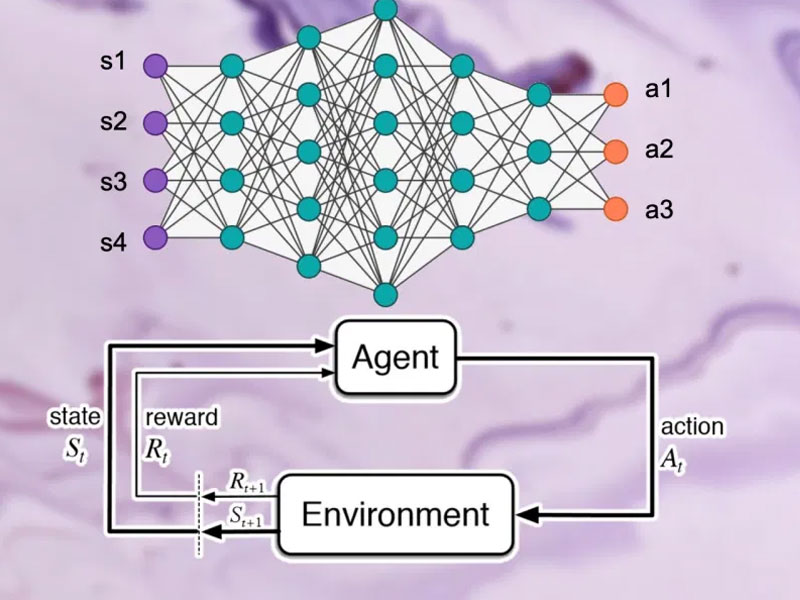
Deep reinforcement learning is one of the most interesting branches of artificial intelligence. It is behind some of the most remarkable achievements of the AI community, including beating human champions at board and video games, self-driving cars, robotics, and AI hardware design.
Deep reinforcement learning leverages the learning capacity of deep neural networks to tackle problems that were too complex for classic RL techniques. Deep reinforcement learning is much more complicated than the other branches of machine learning. But in this post, I’ll try to demystify it without going into the technical details.
At the heart of every reinforcement learning problem are an agent and an environment. The environment provides information about the state of the system. The agent observes these states and interacts with the environment by taking actions. Actions can be discrete (e.g., flipping a switch) or continuous (e.g., turning a knob). These actions cause the environment to transition to a new state. And based on whether the new state is relevant to the goal of the system, the agent receives a reward (the reward can also be zero or negative if it moves the agent away from its goal).
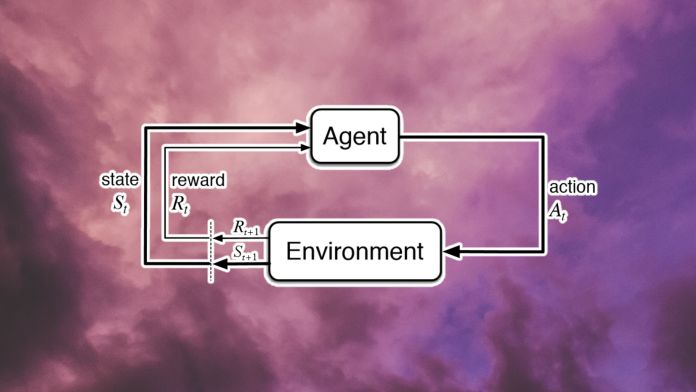
Every cycle of state-action-reward is called a step. The reinforcement learning system continues to iterate through cycles until it reaches the desired state or a maximum number of steps are expired. This series of steps is called an episode. At the beginning of each episode, the environment is set to an initial state and the agent’s reward is reset to zero.
The goal of reinforcement learning is to train the agent to take actions that maximize its rewards. The agent’s action-making function is called a policy. An agent usually requires many episodes to learn a good policy. For simpler problems, a few hundred episodes might be enough for the agent to learn a decent policy. For more complex problems, the agent might need millions of episodes of training.
There are more subtle nuances to reinforcement learning systems. For example, an RL environment can be deterministic or non-deterministic. In deterministic environments, running a sequence of state-action pairs multiple times always yields the same result. In contrast, in non-deterministic RL problems, the state of the environment can change from things other than the agent’s actions (e.g., the passage of time, weather, other agents in the environment).
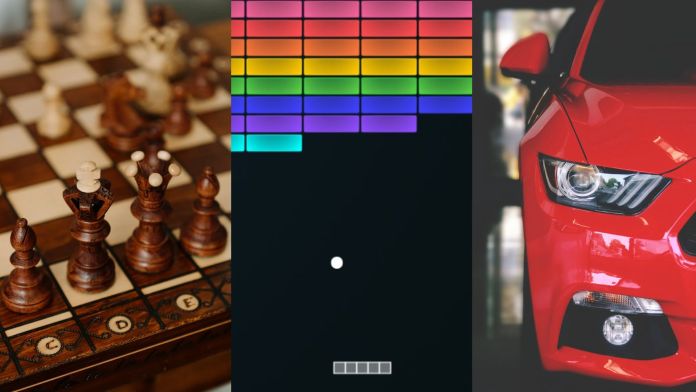
To better understand the components of reinforcement learning, let’s consider a few examples.
Chess: Here, the environment is the chessboard and the state of the environment is the location of chess pieces on the board. The RL agent can be one of the players (alternatively, both players can be RL agents separately training in the same environment). Each game of chess is an episode. The episode starts at an initial state, with black and white pieces lined on the edges of the board. At each step, the agent observes the board (the state) and moves one of its pieces (takes an action), which transitions the environment to a new state. The agent receives a reward for reaching the checkmate state and zero rewards otherwise. One of the key challenges of chess is that the agent doesn’t receive any rewards before it checkmates the opponent, which makes it hard to learn.
Atari Breakout: Breakout is a game where the player controls a paddle. There’s a ball moving across the screen. Every time it hits the paddle, it bounces toward the top of the screen, where rows of bricks have been arrayed. Every time the paddle hits a brick, the brick gets destroyed and the ball bounces back. In Breakout, the environment is the game screen. The state is the location of the paddle and the bricks, and the location and velocity of the ball. The actions that the agent can take are move left, move right, or not move at all. The agent receives a positive reward every time the ball hits a brick and a negative reward if the ball moves past the paddle and reaches the bottom of the screen.
Self-driving cars: In autonomous driving, the agent is the car, and the environment is the world that the car is navigating. The RL agent observes the state of the environment through cameras, lidars, and other sensors. The agent can take navigation actions such as accelerate, hit the brake, turn left or right, or do nothing. The RL agent is rewarded for staying on the road, avoiding collisions, conforming to driving regulations, and staying on course.
Basically, the goal of reinforcement learning is to map states to actions in a way that maximizes rewards. But what exactly does the RL agent learn?
There are three categories of learning algorithms for RL systems:
Policy-based algorithms: This is the most general type of optimization. A policy maps states to actions. An RL agent that learns a policy can create a trajectory of actions that lead from the current state to the objective.
For example, consider an agent that is optimizing a policy to navigate through a maze and reach the exit. First, it starts by making random moves, for which it receives no rewards. In one of the episodes, it finally reaches the exit and receives the exit reward. It retraces its trajectory and readjusts the reward of each state-action pair based on how close it got the agent to the final goal. In the next episode, the RL agent has a better understanding of which actions to take given each state. It gradually adjusts the policy until it converges to an optimal solution.
REINFORCE is a popular policy-based algorithm. The advantage of policy-based functions is that they can be applied to all kinds of reinforcement learning problems. The tradeoff of policy-based algorithms is that they are sample-inefficient and require a lot of training before converging on optimal solutions.
Value-based algorithms: Value-based functions learn to evaluate the value of states and actions. Value-based functions help the RL agent evaluate the possible future return on the current state and actions.
There are two variations to value-based functions: Q-values and V-values. Q functions estimate the expected return on state-action pairs. V functions only estimate the value of states. Q functions are more common because it is easier to transform state-action pairs into an RL policy.
Two popular value-based algorithms are SARSA and DQN. Value-based algorithms are more sample-efficient than policy-based RL. Their limitation is that they are only applicable to discrete action spaces (unless you make some changes to them).
Model-based algorithms: Model-based algorithms take a different approach to reinforcement learning. Instead of evaluating the value of states and actions, they try to predict the state of the environment given the current state and action. Model-based reinforcement learning allows the agent to simulate different trajectories before taking any action.

Model-based approaches provide the agent with foresight and reduce the need for manually gathering data. This can be very advantageous in applications where gathering training data and experience is expensive and slow (e.g., robotics and self-driving cars).
But the key challenge of model-based reinforcement learning is that creating a realistic model of the environment can be very difficult. Non-deterministic environments, such as the real world, are very hard to model. In some cases, developers manage to create simulations that approximate the real environment. But even learning models of these simulated environments ends up being very difficult.
Nonetheless, model-based algorithms have become popular in deterministic problems such as chess and Go. Monte-Carlo Tree Search (MTCS) is a popular model-based method that can be applied to deterministic environments.
Combined methods: To overcome the shortcomings of each category of reinforcement learning algorithms, scientists have developed algorithms that combine elements of different types of learning functions. For example, Actor-Critic algorithms combine the strengths of policy-based and value-based functions. These algorithms use feedback from a value function (the critic) to steer the policy learner (the actor) in the right direction, which results in a more sample-efficient system.

Until now, we’ve said nothing about deep neural networks. In fact, you can implement all the above-mentioned algorithms in any way you want. For example, Q-learning, a classic type of reinforcement learning algorithm, creates a table of state-action-reward values as the agent interacts with the environment. Such methods work fine when you’re dealing with a very simple environment where the number of states and actions are very small.
But when you’re dealing with a complex environment, where the combined number of actions and states can reach huge numbers, or where the environment is non-deterministic and can have virtually limitless states, evaluating every possible state-action pair becomes impossible.
In these cases, you’ll need an approximation function that can learn optimal policies based on limited data. And this is what artificial neural networks do. Given the right architecture and optimization function, a deep neural network can learn an optimal policy without going through all the possible states of a system. Deep reinforcement learning agents still need huge amounts of data (e.g., thousands of hours of gameplay in Dota and StarCraft), but they can tackle problems that were impossible to solve with classic reinforcement learning systems.
For example, a deep RL model can use convolutional neural networks to extract state information from visual data such as camera feeds and video game graphics. And recurrent neural networks can extract useful information from sequences of frames, such as where a ball is headed or if a car is parked or moving. This complex learning capacity can help RL agents to understand more complex environments and map their states to actions.
Deep reinforcement learning is comparable to supervised machine learning. The model generates actions, and based on the feedback from the environment, it adjusts its parameters. However, deep reinforcement learning also has a few unique challenges that make it different from traditional supervised learning.
Unlike supervised learning problems, where the model has a set of labeled data, the RL agent only has access to the outcome of its own experiences. It might be able to learn an optimal policy based on the experiences it gathers across different training episodes. But it might also miss many other optimal trajectories that could have led to better policies. Reinforcement learning also needs to evaluate trajectories of state-action pairs, which is much harder to learn than supervised learning problems where every training example is paired with its expected outcome.
This added complexity increases the data requirements of deep reinforcement learning models. But unlike supervised learning, where training data can be curated and prepared in advance, deep reinforcement learning models gather their data during training. In some types of RL algorithms, the data gathered in an episode must be discarded afterward and can’t be used to further speed up the model tuning process in future episodes.
The AI community is divided on how far you can push deep reinforcement learning. Some scientists believe that with the right RL architecture, you can tackle any kind of problem, including artificial general intelligence. Reinforcement learning is the same algorithm that gave rise to natural intelligence, these scientists believe, and given enough time and energy and the right rewards, we can recreate human-level intelligence.
Others think that reinforcement learning doesn’t address some of the most fundamental problems of artificial intelligence. Despite all their benefits, deep reinforcement learning agents need problems to be well-defined and can’t discover new problems and solutions by themselves, this second group believes.
In any case, what can’t be denied is that deep reinforcement learning has helped solve some very complicated challenges and will continue to remain an important field of interest and research for the AI community for the time being.
Ben Dickson is a software engineer and the founder of TechTalks. He writes about technology, business, and politics.
LATEST NEWS
WHAT'S TRENDING


Data Science
5 Imaginative Data Science Projects That Can Make Your Portfolio Stand Out
OCT 05, 2022

SOURCE: HTTPS://WWW.MARKTECHPOST.COM/
OCT 03, 2023
SOURCE: HTTPS://NEWS.MIT.EDU/
AUG 17, 2023
SOURCE: HTTPS://WWW.SCIENCEDAILY.COM/
AUG 21, 2023
SOURCE: HTTPS://WWW.SCIENCEDAILY.COM/
AUG 17, 2023
SOURCE: HTTPS://WWW.SCIENCEDAILY.COM/
AUG 07, 2023
SOURCE: HTTPS://WWW.INDIATODAY.IN/TECHNOLOGY/NEWS/STORY/69-MILLION-GLOBAL-JOBS-TO-BE-CREATED-IN-NEXT-FIVE-YEARS-AI-AND-MACHINE-LEARNING-ROLES-TO-GROW-IN-INDIA-2367326-2023-05-02
JUN 28, 2023