





Hybrid AI-powered computer vision combines physics and big data
SOURCE: HTTPS://WWW.SCIENCEDAILY.COM/
AUG 14, 2023
DeepMind’s Upgraded Hierarchical Perceiver Is Faster, Scales to Larger Data Without Preprocessing, and Delivers Higher Resolution and Accuracy
SOURCE: SYNCEDREVIEW.COM
FEB 24, 2022
Humans and other biological systems can naturally and simultaneously deal with sensory inputs in a variety of modalities such as vision, audio, touch, proprioception, etc. First proposed at ICML 2021, DeepMind’s Perceiver (Jaegle et al.) was designed to handle arbitrary configurations of different modalities using a single transformer-based architecture. As a general perception system, Perceiver achieves strong performance by using global attention operations on classic classification tasks across these various modalities.
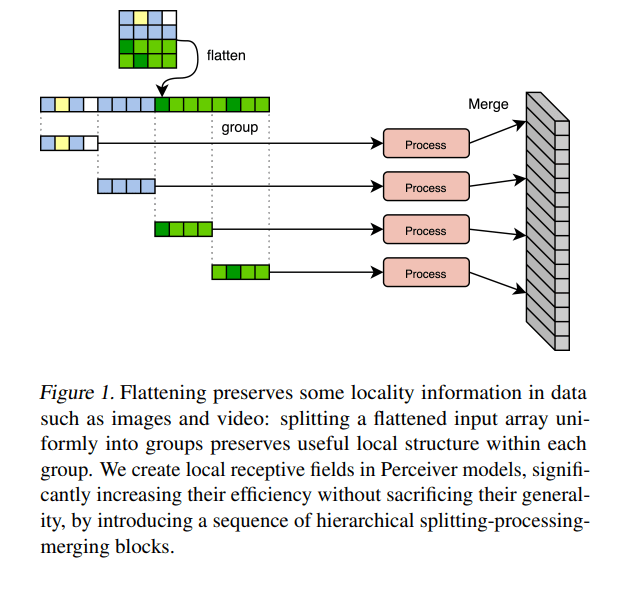
Perceiver models however struggle with the very large input sizes required to process raw high-resolution images or video. To address this issue, a DeepMind research team has proposed Hierarchical Perceiver (HiP), an upgraded model that retains the original Perceiver’s ability to process arbitrary modalities but is faster, can scale up to even more inputs/outputs, reduces the need for input engineering, and improves both efficiency and accuracy on classical computer vision benchmarks.

Perceivers handle diverse raw inputs by adapting transformers to operate on a latent bottleneck space. Although they can deal with significantly larger input and output spaces and achieve competitive results in various domains, including audio, text and images, existing Perceiver models still require domain-specific preprocessing such as patching or convolutions for very large signals like high-resolution images or videos.

The team designed HiP to solve the abovementioned limitations while maintaining the advantages of previous Perceivers based on two key ideas:

To utilize local structures to improve model efficiency, the researchers grouped inputs to the block by splitting them into several groups, and organized the blocks in a hierarchical manner such that each block treats the previous block’s output as input, grouping and processing accordingly. To generate dense outputs, they generalized the Perceiver IO version (Jaegle et al., 2021) and constructed a reverse hierarchy of layers for decoding. For HiP’s depth and width design, the team used more channels deeper in the model (where “resolution” is lower) to introduce a useful inductive bias and more efficiency. This approach differs from traditional transformer architectures, which typically keep a constant number of channels in all layers. Finally, they applied sum-type skip connections between the encoder and decoder before the cross-attention layers to stabilize training in masked auto-encoding and obtain slightly lower losses.
The researchers created two model configurations: HiP-256; and HiP-16, which has slightly shallower hierarchical encoder/decoder modules. They conducted evaluation experiments on the ImageNet, Audioset and PASCAL VOC datasets.



In the empirical evaluations, HiP-16 achieved 81.0 percent accuracy on ImageNet from pixels for image classification tasks, bettering Perceiver IO’s 79.9 percent accuracy; while HiP-256 outperformed the original Perceiver on AudioSet using raw audio. Both HiP versions obtained an mIoU (mean intersection-over-union) score on par with the convolutional ResNet-50 baseline on PASCAL VOC semantic segmentation tasks. Overall, the results validate the effectiveness of the proposed HiP models in favourably bridging the Perceiver and transformer families of model families and enforcing a loose, modality-agnostic local connectivity.
The paper Hierarchical Perceiver is on arXiv.
Author: Hecate He | Editor: Michael Sarazen
LATEST NEWS
Augmented Reality
Hi-tech smart glasses connecting rural and remote aged care residents to clinicians
NOV 20, 2023
WHAT'S TRENDING


Data Science
5 Imaginative Data Science Projects That Can Make Your Portfolio Stand Out
OCT 05, 2022

SOURCE: HTTPS://WWW.SCIENCEDAILY.COM/
AUG 14, 2023


SOURCE: INDIANEXPRESS.COM
OCT 24, 2022



