





AI language models could help diagnose schizophrenia
SOURCE: HTTPS://WWW.SCIENCEDAILY.COM/
OCT 09, 2023
Cancer Research Inspires Improved Training Models for Natural Language Processing
SOURCE: HPCWIRE.COM
SEP 15, 2022
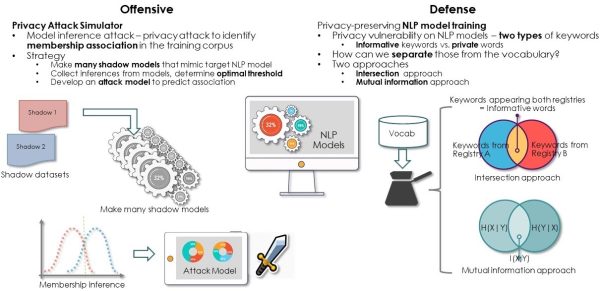
Sept. 15, 2022 — The use of artificial intelligence/machine learning (AI/ML) methods to analyze health information brings great promise for learning about disease but also great risk to patient privacy. New natural language processing deep learning model training methods developed by an Exascale Computing Project–funded team will help secure private textual information used for health care, homeland security, biomedical sciences, environmental, and social behavioral research.

Method to ensure privacy in natural language processing models for cancer and other PII data. The ECP-funded team explored intersection and mutual information approaches. Credit: ECP.
Their work offers a method for quantifying privacy vulnerability of training models used in sensitive research areas and for decreasing privacy vulnerability while maintaining clinical task performance. Models were trained in the ECP’s Cancer Distributed Learning Environment, and cancer registry data was accessed from the National Cancer Institute’s Surveillance, Epidemiology, and End Results Program. The researchers’ work was published in the January 2022 issue of Cancer Biomarkers.
Models for cancer research using patient records may be trained on personally identifiable information, or PII, ensuring classification accuracy but exposing private health details. The researchers simulated membership inference attacks using a multitask convolutional neural network to test their method’s effectiveness in determining whether private data from state population-based cancer registries were included in their model’s training data.
To solve the privacy vulnerability problem, they tested two approaches for selecting informative keywords (i.e., those relevant to the research question) that would not expose private data. The intersection approach selects training data containing keywords and tokens that occur across multiple registries, and the mutual intersection approach quantifies how closely training data is associated with private information in the dataset. In tests, the researchers found the intersection approach preserved data privacy while maintaining task performance but noted it requires accessing multiple datasets. The mutual information approach allowed them to control data security
To reduce privacy vulnerability, the team recommended increasing training data volume, curating deep learning models’ informative keyword vocabulary, and training models with the curated vocabulary to avoid overfitting. Future work includes exploring the privacy and security challenges posed by new paradigms such as federated learning, which involves cooperatively training AI/ML models across multiple, decentralized secure sites or servers that do not exchange the secure data. The team will work to identify potential privacy attacks and leakage, develop simulation tests of those vulnerabilities, and establish secure AI/ML training protocols in the new environments.
The Paper: Hong-Jun Yoon, Christopher Stanley, J. Blair Christian, Hilda B. Klasky, Andrew E. Blanchard, Eric B. Durbin, Xiao-Cheng Wu, Antoinette Stroup, Jennifer Doherty, Stephen M. Schwartz, Charles Wiggins, Mark Damesyn, Linda Coyle, and Georgia D. Tourassi. “Optimal Vocabulary Selection Approaches for Privacy-Preserving Deep NLP Model Training for Information Extraction and Cancer Epidemiology.” 2022. Cancer Biomarkers (January). DOI: 10.3233/CBM-210306.
LATEST NEWS
Augmented Reality
Hi-tech smart glasses connecting rural and remote aged care residents to clinicians
NOV 20, 2023
WHAT'S TRENDING


Data Science
5 Imaginative Data Science Projects That Can Make Your Portfolio Stand Out
OCT 05, 2022

SOURCE: HTTPS://WWW.SCIENCEDAILY.COM/
OCT 09, 2023
SOURCE: HTTPS://WWW.THEROBOTREPORT.COM/
SEP 30, 2023
SOURCE: HTTPS://WWW.SCIENCEDAILY.COM/
AUG 08, 2023



SOURCE: HOUSTON.INNOVATIONMAP.COM
OCT 03, 2022

SOURCE: MEDCITYNEWS.COM
OCT 06, 2022