




{kind=link}
{kind=link}
{kind=link}
{kind=link}

CMU Researchers Introduce the Open Whisper-Style Speech Model: Advancing Open-Source Solutions for Efficient and Transparent Speech Recognition Training
SOURCE: HTTPS://WWW.MARKTECHPOST.COM/
OCT 03, 2023
A complete guide to weak supervision in machine learning
SOURCE: ANALYTICSINDIAMAG.COM
OCT 03, 2021

Amachine learning model works accurately when the given data precisely covers the domain for which the model is designed and is structured according to the features of the model. Since most of the data available are in an unstructured or low structured format, to proceed with annotation of this type of data employs the concept of weak supervision in machine learning. Mainly if the data is annotated but in low-quality, weak supervision comes into the picture. In this article, we will try to understand the weak supervision in detail along with the approach and strategies to perform weak supervision. The major points to be covered in this article are listed below.
Table of Contents
Let us begin with understanding the weak supervision.
What is Weak supervision?
Weak supervision is a part of machine learning where unorganized or imprecise data are used to provide indications to label a large amount of unsupervised data so that a large amount of data can be used in machine learning or supervised learning. More formally we can say that the indication is a kind of supervision signal for labelling the unlabeled data. As we know obtaining hand-labelled datasets is so costly and time-consuming, this approach tries to reduce the efforts in hand labelling of data by providing labels to some data and using some data to provide the labels to unlabeled data.
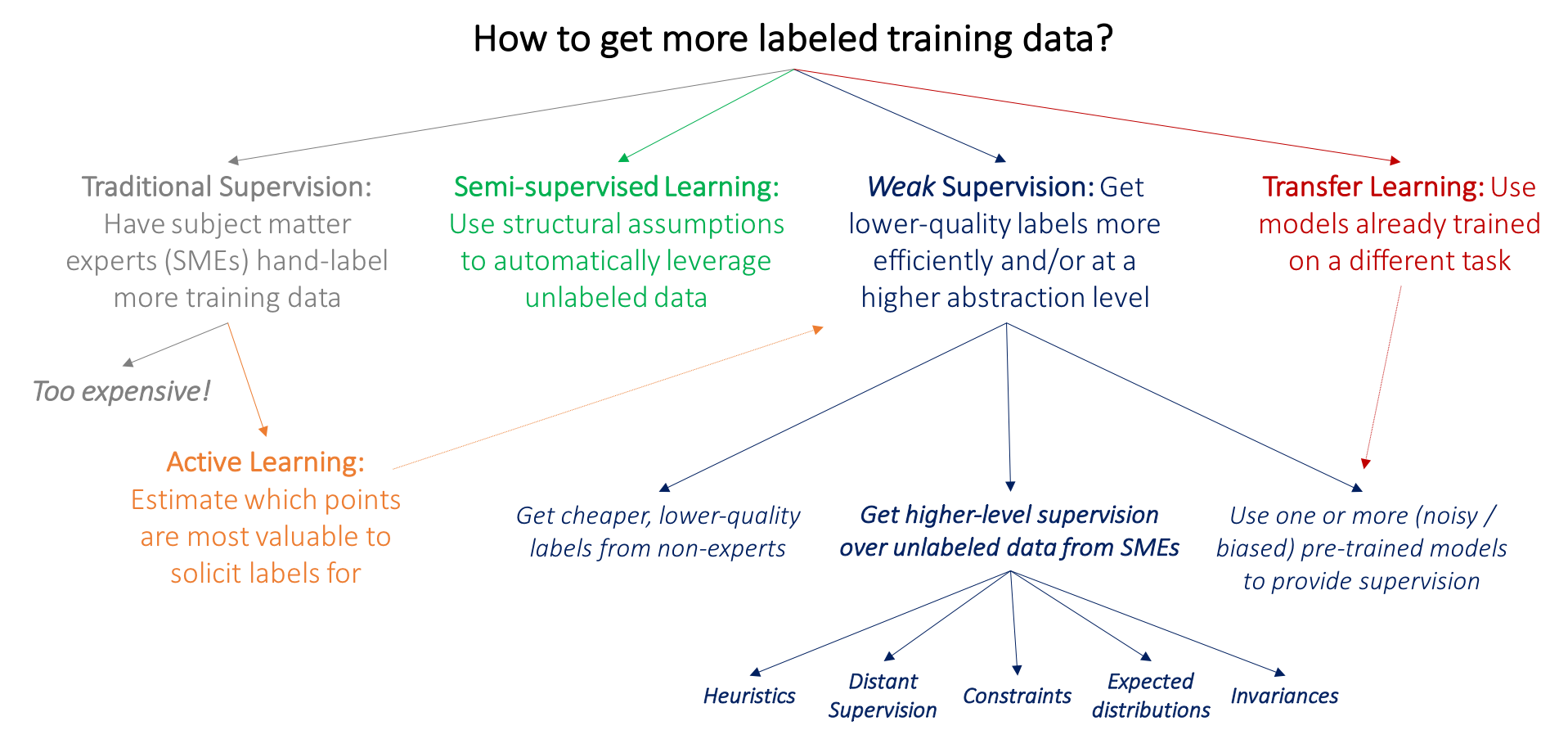
Especially in natural language processing where we have many patterns specific to the data which causes a pre-trained model to not perform well with specific patterns. In such cases, weak supervision helps in enhancing the performance of the model regarding the patterns. making data applicable for modeling requires a huge amount of effort, time, and money. In accordance to make a dataset structured, we can divide the data annotation levels in three-part where if the data is highly annotated we can directly proceed for the modeling procedure where the model can belong to supervised learning(if data is big), unsupervised learning, and transfer learning (if the data is small), if the data is not annotated we follow the unsupervised learning procedures like clustering, PCA, etc and The below image represents the overview of why we need weak supervision.
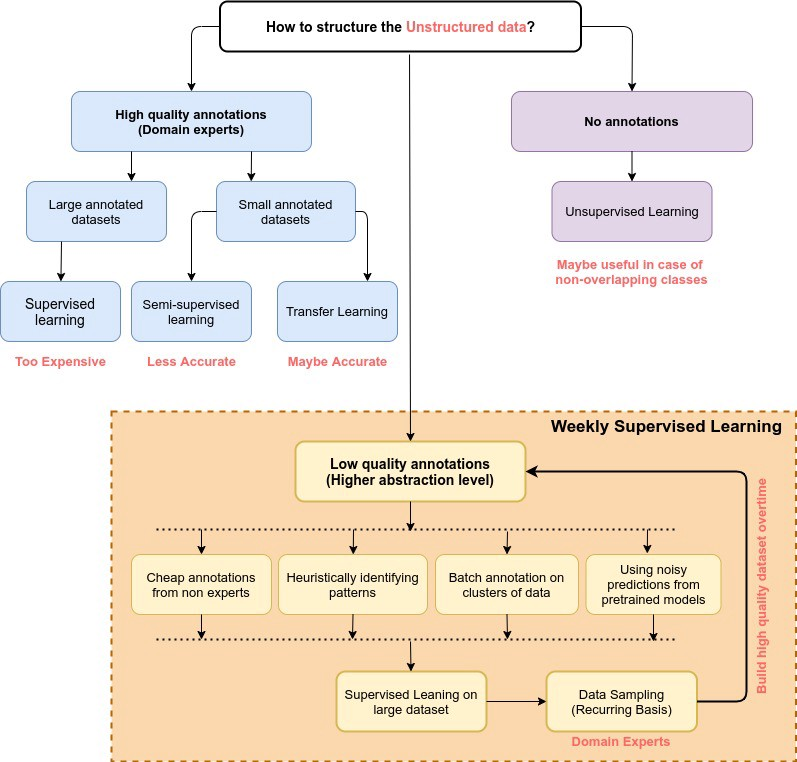
Evolution of Weak Supervision
At the start, the main focus of the AI was on the expert system. In which combination of the knowledge base of SME with inference engine included. Where in the middle era of artificial intelligence models started completed tasks based on labelled data in powerful and flexible ways. Where the classical ML approaches were introduced which mainly consisted of two ways to put knowledge base from domain experts. The first is to provide a low amount of hand-labelled data to models from the domain experts and the second is to provide hand-engineered features so that features can deal with the model’s base representation of the data.
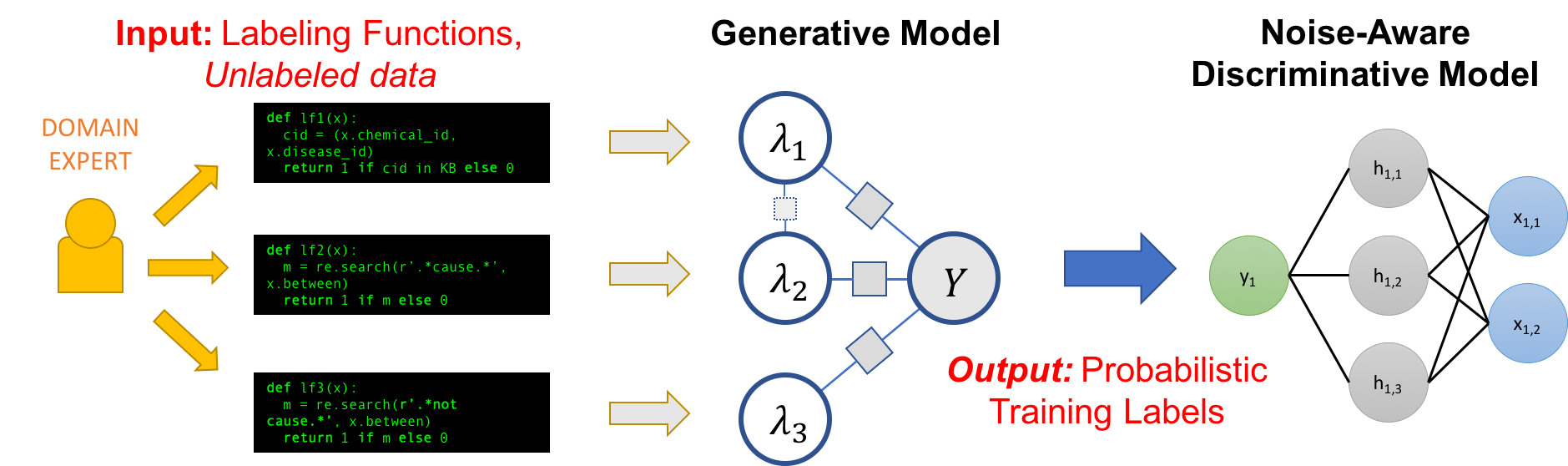
Where in the modern era the deep learning projects are in the boom because of their ability to learn representations across many domains and tasks. These models are not only providing ease in feature engineering but also many systems are generated to make the data labelled automatically like snorkel is a system that supports and explores the interaction with machine learning. The system asks for only labelling functions, black box snippets of code which helps in labelling the subsets of unlabeled data. So this is how from a basic part of weak supervision to an advanced part of the supervision, weak supervision has evolved, and still, people are trying to perform more on the field finding new ways to improve the weak supervision.

Problems with Labeled Training Data
Following are the major problems with labelled training data:-
Insufficient quantity of labelled data
In the initial stages of training of the machine learning, models are dependent on the labelled data and the issues are most of the data was unlabeled or not enough to apply on the models for better training. Obtaining training data was almost impractical, expensive, or time-consuming.
Insufficient subject-matter expertise to label data
When it comes to giving labels to unlabeled data we require a person or a team of subject matter expertise. Instead of having such facilities human intervention in the labelling of the data requires a lot of time and the cost of the SME is also included. Which makes the process impractical.
Insufficient time to label and prepare data
Before implementation of a machine learning model in any data the task of preprocessing the data is mandatory for better performance. When it comes to real-life experiences we have a lot of data but not every data is that prepared so it can be deployed on the model. It is nearly impossible to make accurate data quickly according to the model.
To get over all these problems we require some rigid and reliable approaches so that we can perform a major part of data preprocessing which is data labelling.
How to Get More Labeled Training Data?
In any situation, this is the most traditional approach to getting labelled data where we have we hire the SME(subject matter expert) to label the data but when things come with the large unlabelled datasets then the process becomes so much expensive and hard for a person or group of person to provide the labels. In such a scenario to reduce the efforts we basically follow three main approaches :

The above-given approaches surely help in reducing the efforts of labelling the data. In the above-given image, we can see how weak supervision helps in covering the drawbacks of other approaches. Based on label type, we can classify the weak labels in a below-given manner.
Types of Weak Labels
There are three main types of weak labels:-
Imprecise or Inexact Labels: this type of label can be obtained by an active learning approach where the subject matter expertise gives less precise labels to the data to developers. And then the developers can use weak labels to create rules, define distributions, apply other constraints on the training data
Inaccurate Labels: this type of label can be obtained by semi-supervised learning where the labels on the data sets can be of lower quality labels by some expensive means like crowdsourcing. developers may use obtained labels by regularizing the decision boundaries of the model. such labels that are numerous, but not perfectly accurate.
Existing Labels: this type of label can be obtained from the existing resources like knowledge base, alternative data for training, or from the data used in the pre-trained model. These labels can be used by developers but they are not perfectly applicable for the task given to the model. In such a scenario using a pre-trained model is beneficial.
Basic System Features to Support Weak Supervision
As of now we have seen what can be the specification of the weak supervision and can easily understand the features any system can consist of, which is made to support the weak supervision. We can say that labelling the data using some function can give noisy output. We require some function to label the data and models to find out the measurement of the accuracy of labelling. A system can comprise of three features:

Final Words
In the article, we have seen what weak supervision is along with its evolution in three parts. Also, we got to know the problems given by the unlabeled data in the modelling and what can be the approaches to make the data labelled and if a system is generated to support the weak supervision and what should be the primary features of it to help in performing weak supervision.
LATEST NEWS
Augmented Reality
Hi-tech smart glasses connecting rural and remote aged care residents to clinicians
NOV 20, 2023
WHAT'S TRENDING


Data Science
5 Imaginative Data Science Projects That Can Make Your Portfolio Stand Out
OCT 05, 2022

SOURCE: HTTPS://WWW.MARKTECHPOST.COM/
OCT 03, 2023
SOURCE: HTTPS://NEWS.MIT.EDU/
AUG 17, 2023
SOURCE: HTTPS://WWW.SCIENCEDAILY.COM/
AUG 21, 2023
SOURCE: HTTPS://WWW.SCIENCEDAILY.COM/
AUG 17, 2023
SOURCE: HTTPS://WWW.SCIENCEDAILY.COM/
AUG 07, 2023
SOURCE: HTTPS://WWW.INDIATODAY.IN/TECHNOLOGY/NEWS/STORY/69-MILLION-GLOBAL-JOBS-TO-BE-CREATED-IN-NEXT-FIVE-YEARS-AI-AND-MACHINE-LEARNING-ROLES-TO-GROW-IN-INDIA-2367326-2023-05-02
JUN 28, 2023