





CMU Researchers Introduce the Open Whisper-Style Speech Model: Advancing Open-Source Solutions for Efficient and Transparent Speech Recognition Training
SOURCE: HTTPS://WWW.MARKTECHPOST.COM/
OCT 03, 2023
A beginner’s guide to extreme learning machine
SOURCE: ANALYTICSINDIAMAG.COM
OCT 03, 2021

The learning pace of the feed-forward neural networks is considered as much slower than required. Due to this limitation, it has been a major barrier in many applications for decades. One of the major reasons is that sluggish gradient-based learning algorithms are widely employed to train neural networks which iteratively tune all of the network’s parameters and makes the learning process slower. Unlike standard learning approaches, there is a learning technique for Single-Hidden Layer Feed-Forward Neural Networks (SLFNs) that is called Extreme Learning Machine (ELM). The ELMs are believed to have the ability to learn thousands of times faster than networks trained using the backpropagation technique. In this article, we will discuss ELM in detail. The major points that we will cover in this article are listed below.
Let’s proceed with understanding Feed-Forward NN.
The feedforward neural network was the earliest and most basic type of artificial neural network to be developed. In this network, information flows only in one direction forward from the input nodes to the output nodes, passing via any hidden nodes. The network is devoid of cycles or loops.
A single-layer perceptron network is the simplest type of FeedForward neural network, consisting of a single layer of output nodes with the inputs fed straight to the outputs via a sequence of weights. Each node calculates the total of the weights and inputs, and if the value is greater than a threshold (usually 0), the neuron fires and takes the active value (commonly 1); otherwise, it takes the deactivated value (typically 0 or -1). Artificial neurons or linear threshold units are neurons with this type of activation function. The term perceptron is frequently used in the literature to refer to networks that contain only one of these components.
Extreme learning machines are feed-forward neural networks having a single layer or multiple layers of hidden nodes for classification, regression, clustering, sparse approximation, compression, and feature learning, where the hidden node parameters do not need to be modified. These hidden nodes might be assigned at random and never updated, or they can be inherited from their predecessors and never modified. In most cases, the weights of hidden nodes are usually learned in a single step which essentially results in a fast learning scheme.
These models, according to their inventors, are capable of producing good generalization performance and learning thousands of times quicker than backpropagation networks. These models can also outperform support vector machines in classification and regression applications, according to the research.
An ELM is a quick way to train SLFN networks (shown in the below figure). An SLFN comprises three layers of neurons, however, the name Single refers to the model’s one layer of non-linear neurons which is the hidden layer. The input layer offers data features but does not do any computations, whereas the output layer is linear with no transformation function and no bias.
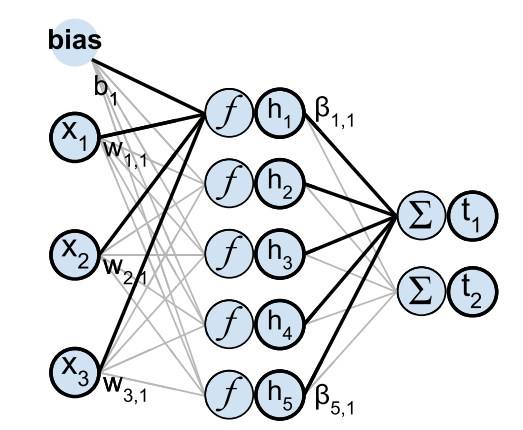
The ELM technique sets input layer weights W and biases b at random and never adjusts them. Because the input weights are fixed, the output weights ???? are independent of them (unlike in the Backpropagation training method) and have a straightforward solution that does not require iteration. Such a solution is also linear and very fast to compute for a linear output layer.
Random input layer weights improve the generalization qualities of a linear output layer solution because they provide virtually orthogonal (weakly correlated) hidden layer features. A linear system’s solution is always in a range of inputs. If the solution weight range is constrained, orthogonal inputs provide a bigger solution space volume with these constrained weights. Smaller weight norms tend to make the system more stable and noise resistant since input errors are not aggravating in the output of the linear system with smaller coefficients. As a result, the random hidden layer creates weakly correlated hidden layer features, allowing for a solution with a low norm and strong generalization performance.
In this section, we will summarize several variants of ELM and will introduce them briefly.
ELM for Online Learning
There are numerous types of data in real-world applications, thus ELM must be changed to effectively learn from these data. For example, because the dataset is increasing, we may not always be able to access the entire dataset. From time to time, new samples are added to the dataset. Every time the set grows, we must retrain the ELM.
However, because the new samples frequently account for only a small portion of the total, re-training the network using the entire dataset again is inefficient. Huang and Liang proposed an online sequential ELM to address this issue (OS-ELM). The fundamental idea behind OS-ELM is to avoid re-training over old samples by employing a sequential approach. OS-ELM can update settings over new samples consecutively after startup. As a result, OS-ELM can be trained one at a time or block by block.
Incremental ELM
To build an incremental feedforward network, Huang et al. developed an incremental extreme learning machine (I-ELM). When a new hidden node was introduced, I-ELM randomly added nodes to the hidden layer one by one, freezing the output weights of the existing hidden nodes. I-ELM is effective for SLFNs with piecewise continuous activation functions (including differentiable) as well as SLFNs with continuous activation functions ( such as threshold).
Pruning ELM
Rong et al. proposed a pruned-ELM (P-ELM) algorithm as a systematic and automated strategy for building ELM networks in light of the fact that using too few/many hidden nodes could lead to underfitting/overfitting concerns in pattern categorization. P-ELM started with a large number of hidden nodes and subsequently deleted the ones that were irrelevant or lowly relevant during learning by considering their relevance to the class labels.
ELM’s architectural design can thus be automated as a result. When compared to the traditional ELM, simulation results indicated that the P-ELM resulted in compact network classifiers that generate fast response and robust prediction accuracy on unseen data.
Error-Minimized ELM
Feng et al. suggested an error-minimization-based method for ELM (EM-ELM) that can automatically identify the number of hidden nodes in generalized SLFNs by growing hidden nodes one by one or group by group. The output weights were changed incrementally as the networks grew, reducing the computational complexity dramatically. The simulation results on sigmoid type hidden nodes demonstrated that this strategy may greatly reduce the computational cost of ELM and offer an ELM implementation that is both efficient and effective.
Evolutionary ELM
When ELM is used, the number of hidden neurons is usually selected at random. Due to the random determination of input weights and hidden biases, ELM may require a greater number of hidden neurons. Zhu et al. introduced a novel learning algorithm called evolutionary extreme learning machine (E-ELM) for optimizing input weights and hidden biases and determining output weights.
To improve the input weights and hidden biases in E-ELM, the modified differential evolutionary algorithm was utilized. The output weights were determined analytically using Moore– Penrose (MP) generalized inverse.
Extreme learning machine has been used in many application domains such as medicine, chemistry, transportation, economy, robotics, and so on due to its superiority in training speed, accuracy, and generalization. This section highlights some of the most common ELM applications.
IoT Application
As the Internet of Things (IoT) has gained more attention from academic and industry circles in recent years, a growing number of scientists have developed a variety of IoT approaches or applications based on modern information technologies.
Using ELM in IoT applications can be done in a variety of ways. Rathore and Park developed an ELM-based strategy for detecting cyber-attacks. To identify assaults from ordinary visits, they devised a fog computing-based attack detection system and used an updated ELM as a classifier.
Transportation Application
The application of machine learning in transportation is a popular issue. Scientists, for example, used machine learning techniques to create a driver sleepiness monitoring system to prevent unsafe driving and save lives. It’s been a long time since an extreme learning machine was used to solve transportation-related challenges. Sun and Ng suggested a two-stage approach to transportation system optimization that integrated linear programming and extreme learning machines. Two trials showed that combining their approaches might extend the life of a transportation system while also increasing its reliability.
In this post, we learned about the extreme learning machine (ELM) and we have seen the methodology of ELM. We also discussed how it is different from the conventional approach. Along with its fundamental principles, we also came to know about its variants along with how researchers from different domains leverage the power of ELM.
LATEST NEWS
WHAT'S TRENDING


Data Science
5 Imaginative Data Science Projects That Can Make Your Portfolio Stand Out
OCT 05, 2022

SOURCE: HTTPS://WWW.MARKTECHPOST.COM/
OCT 03, 2023
SOURCE: HTTPS://NEWS.MIT.EDU/
AUG 17, 2023
SOURCE: HTTPS://WWW.SCIENCEDAILY.COM/
AUG 21, 2023
SOURCE: HTTPS://WWW.SCIENCEDAILY.COM/
AUG 17, 2023
SOURCE: HTTPS://WWW.SCIENCEDAILY.COM/
AUG 07, 2023
SOURCE: HTTPS://WWW.INDIATODAY.IN/TECHNOLOGY/NEWS/STORY/69-MILLION-GLOBAL-JOBS-TO-BE-CREATED-IN-NEXT-FIVE-YEARS-AI-AND-MACHINE-LEARNING-ROLES-TO-GROW-IN-INDIA-2367326-2023-05-02
JUN 28, 2023